Fivetran High-Volume Agent Connector で SQL Server のデータを Snowflake に同期してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
Fivetran では High-Volume Agent(以降、HVA とします)として特に大規模なデータ向けに、リアルタイム データ レプリケーションのためのソリューションを提供しています。このうち SQL Server 向けに提供されている High-Volume Agent SQL Server を試してみましたので記事としました。
HVA の概要
HVA の概要は以下に記載があります。
アーキテクチャ
HVA はソースシステム側(大抵は同じマシン)にインストールすることでエージェントとして機能します。
エージェントは、ソースからの変更データのキャプチャやその管理を担います。ソースシステム側にあることで、直接変更データにアクセスできるため遅延を最小限に抑えつつ、エージェントからのデータ転送時には、データの暗号化・圧縮を行い、データ転送時の効率を高めます。
そのため、キャプチャ対象のデータテーブルが数千あるような大規模なデータソースで使用される場合があります。
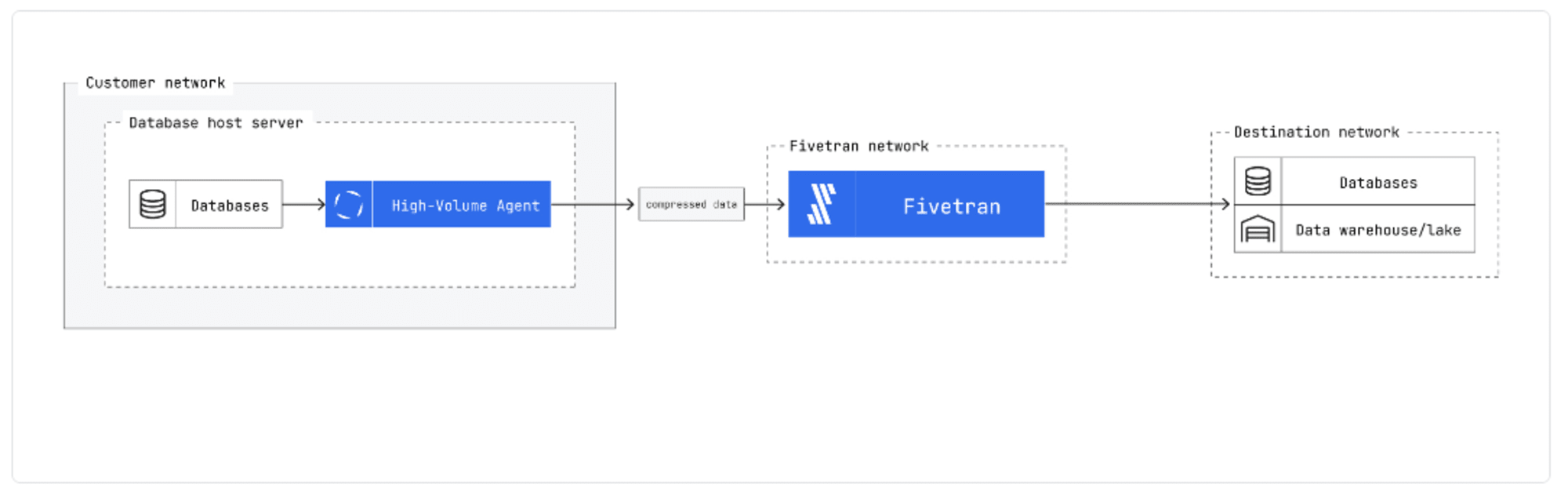
※図は上記のドキュメントより引用
システム要件
- OS
- Linux や Windows OS にもインストール可能
- CPU
- 各増分同期でシステム内の最大1つの CPU コアを使用
- 特にログ解析時にリソースを消費し、CDC がログの現在のポイントに到達するまで、単一の CPU コアを 100% 使用する可能性がある
- メモリ
- 処理中の各トランザクションに対して最大 64 MBのメモリを消費
- ストレージ
- インストールサイズは約135MB
- 実行中のメモリ使用量が 64MB 超えるとディスクを使用するため、設定フォルダ(
HVR_CONFIG)には最低 5GB のディスクスペースを確保することが推奨されています
- 権限
- Windows の場合、以下のいずれかのユーザーアカウントでの実行が必要
- ソース SQL Server サービスと同じ Windows ユーザーアカウント
- Debug programs (SeDebugPrivilege) ポリシーが有効化されたアカウント(Administrators グループのユーザーは、このデバッグ権限をデフォルトで保持)
- また、ユーザーアカウントで「サービスとしてログオン」ポリシーが有効になっている必要があります
- Windows の場合、以下のいずれかのユーザーアカウントでの実行が必要
エージェントへの接続方法
HVA を使用する場合、Fivetran 側のデータ処理サーバーはソースシステムではなく HVA に接続します。つまり、ソースシステムには HVA が接続を行います。HVA への接続は通常のコネクタ使用時と同様に以下の方法を使用可能です。
- 直接接続
- SSH トンネル
- Virtual Private Network
- Private networking(AWS PrivateLink, Azure Private Link, Google Cloud Private Service Connect)
また、この際デフォルトポートとして4343が使用されます。
サポートされるデータソース
2024年8月時点では、以下のソースシステムをサポートしています。
- Db2 for i ※ベータ版
- Oracle
- SQL Server
- SAP ERP
- SAP ECC on Oracle ※ベータ版
- SAP ECC on Oracle with NetWeaver ※ベータ版
- SAP ECC on SQL Server ※ベータ版
HVA SQL Server
SQL Server をソースに HVA を使用する際の前提条件は以下に記載があります。
主な項目は以下です。
- サポートする SQL Server バージョン
- Windows Server 上の SQL Server
- SQL Server 2012 - 2022
- Linux 上の SQL Server
- SQL Server 2017 - 2019
- Windows Server 上の SQL Server
- 復旧モデル
- 完全(Full)のみ
- 復旧モデル (SQL Server) - SQL Server
- 増分更新の方法
- Direct Capture:SQL Serverのオンライントランザクションログから直接変更をキャプチャ
- Archive Log Only:トランザクションログのバックアップから変更をキャプチャ
- この方法の場合、SQL Server のインストール先と異なるしているマシンに HVA をインストール可能
- ただし、Archive Log Only はログバックアップファイルが作成されたときにのみ変更をキャプチャするため、遅延がしやすくなる傾向がある
検証環境
ここでは以下の環境で検証を行いました。
- 宛先:Snowflake
- データソース
- Windows Server 2019 上にインストールした SQL Server 2022 Developer
- Windows Server
- プライベートサブネットに構築
- インスタンスタイプ:t2.xlarge
- 4 vCPU 16GB メモリ
- ストレージ
- C(OS, SQL Server):50 GB
- D(HVA):10 GB
- 接続方法
- SSH トンネル
- SSH サーバー
- パブリックサブネットに構築
- OS:Amazon Linux 2023
- インスタンスタイプ:t2.micro
- データの更新方法
- Direct Capture
Snowflake を宛先として設定する手順は以下をご参照ください。
また、Windows Server を構築後、以下の作業を実施しておきます。
- Windows Defender ファイアウォール の無効化
- ボリュームの追加
ここでは検証のため SSH サーバーをそのまま踏み台として使用しました。踏み台経由でのリモートデスクトップ接続の手順は以下をご参照ください。
HVA のインストール・設定
インストールや設定の手順は以下に記載があるのでこちらに沿って進めました。
インストール
インストーラーは Fivetran ダッシュボードのダウンロードページよりダウンロード可能です。取得後、インストーラーを実行し、[Next] をクリックします。
規約に同意し [Next] をクリックします。
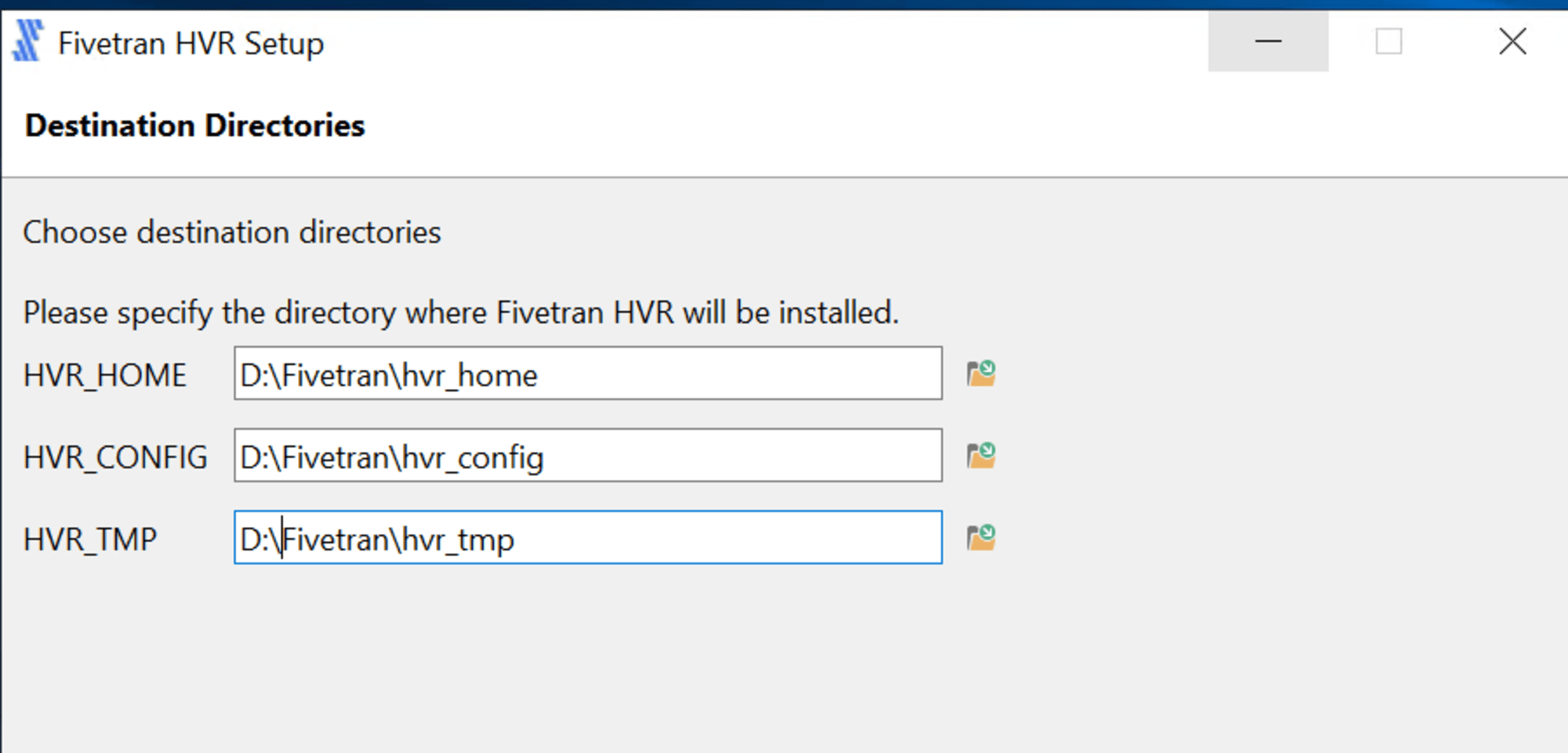
インストール先を指定します。デフォルトは下図の通りです。
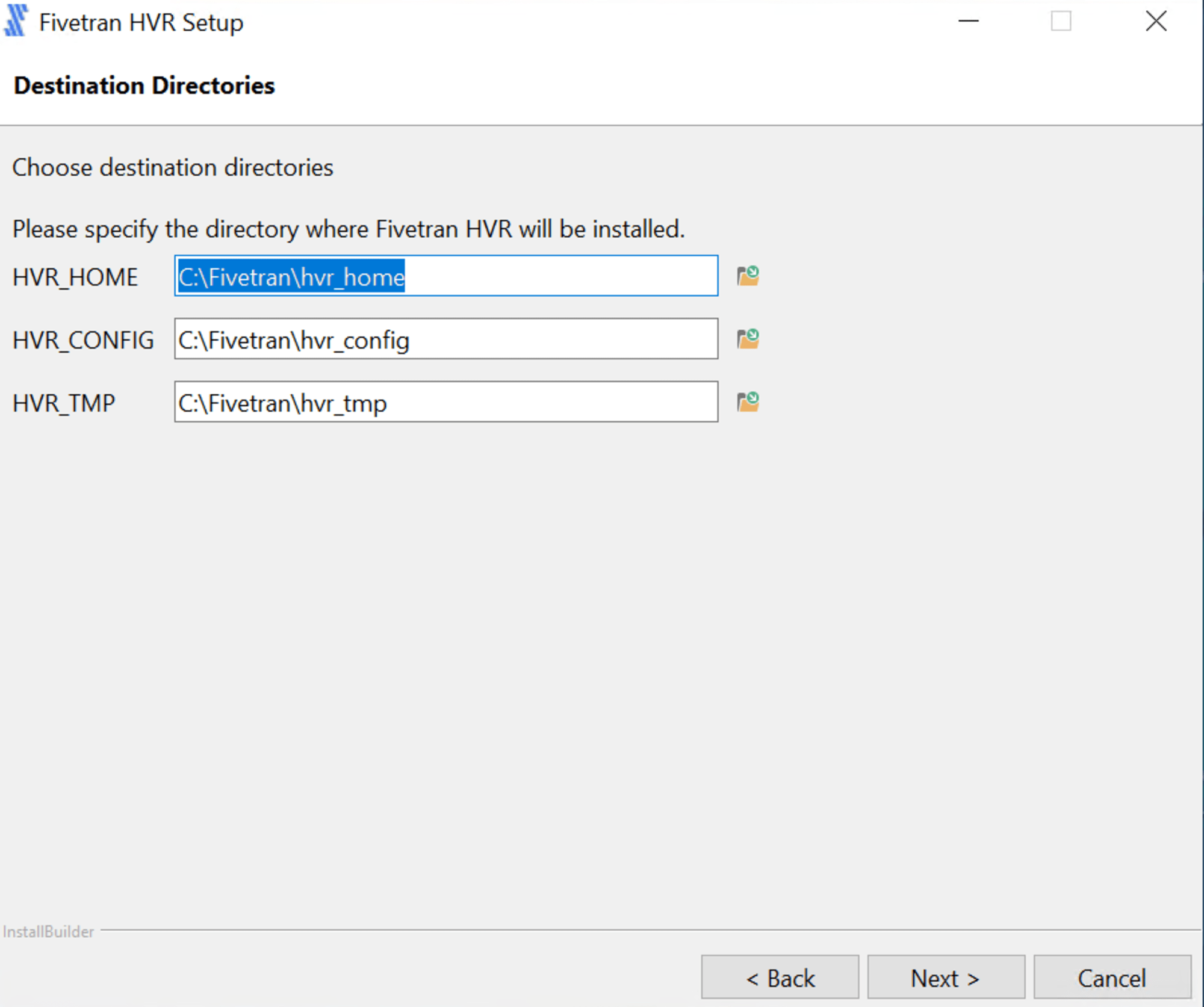
ここでは、以下の通りインストール先を変更しました。
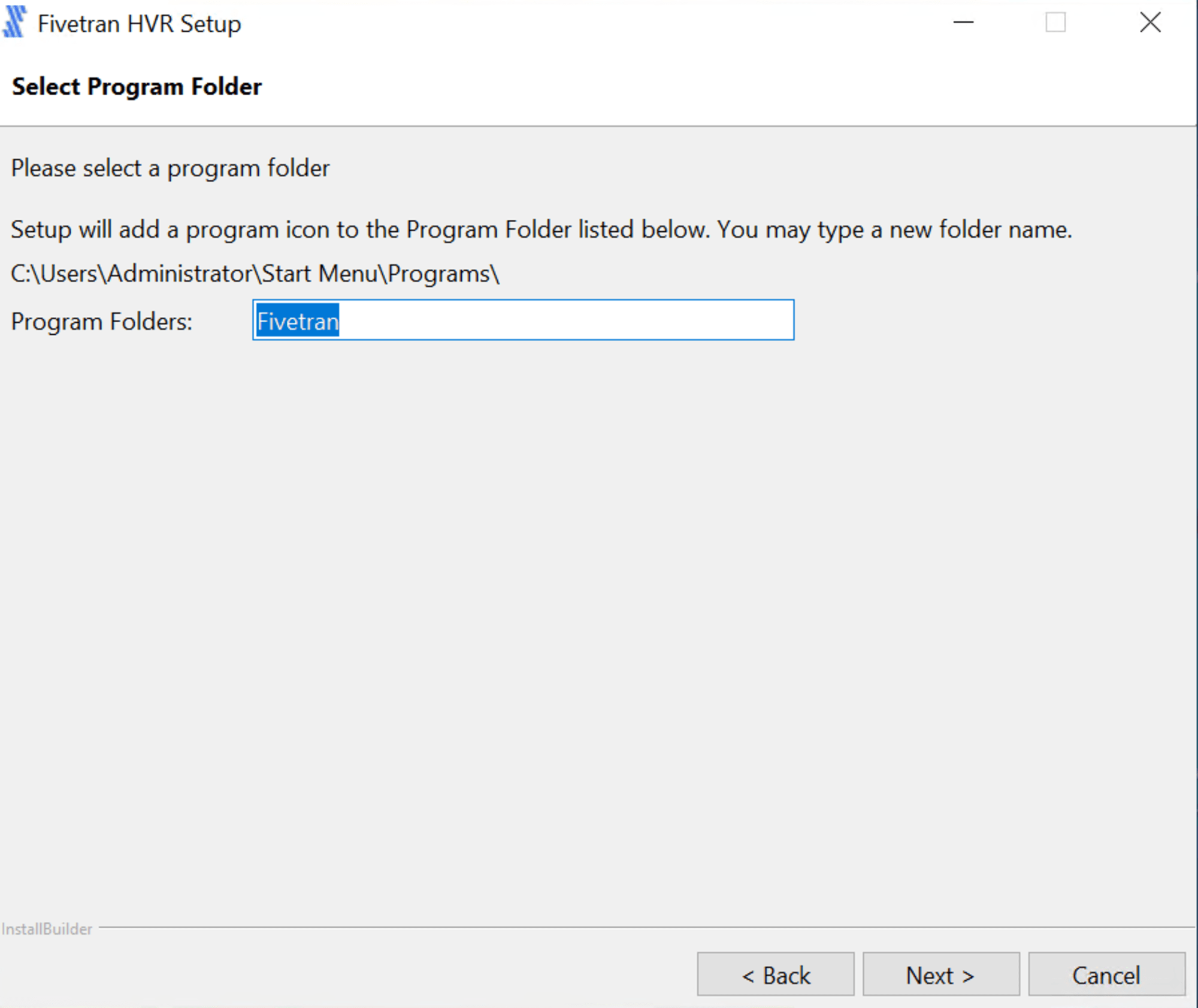
プログラムフォルダの名称を指定します。
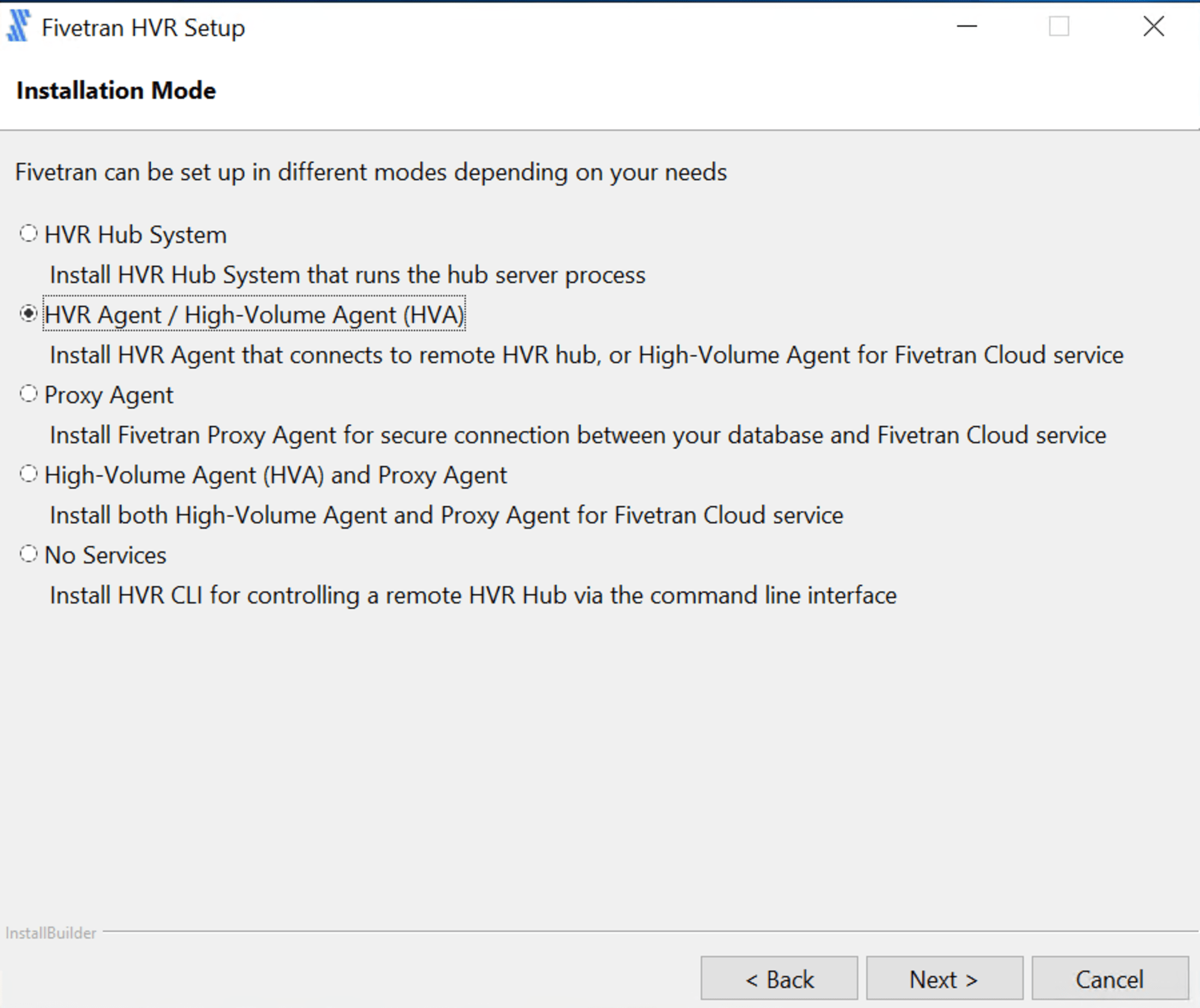
インストールのモードを選択します。HVA としての利用なので「HVR Agent / High-Volume Agent(HVA)」を選択し [Next] をクリックします。
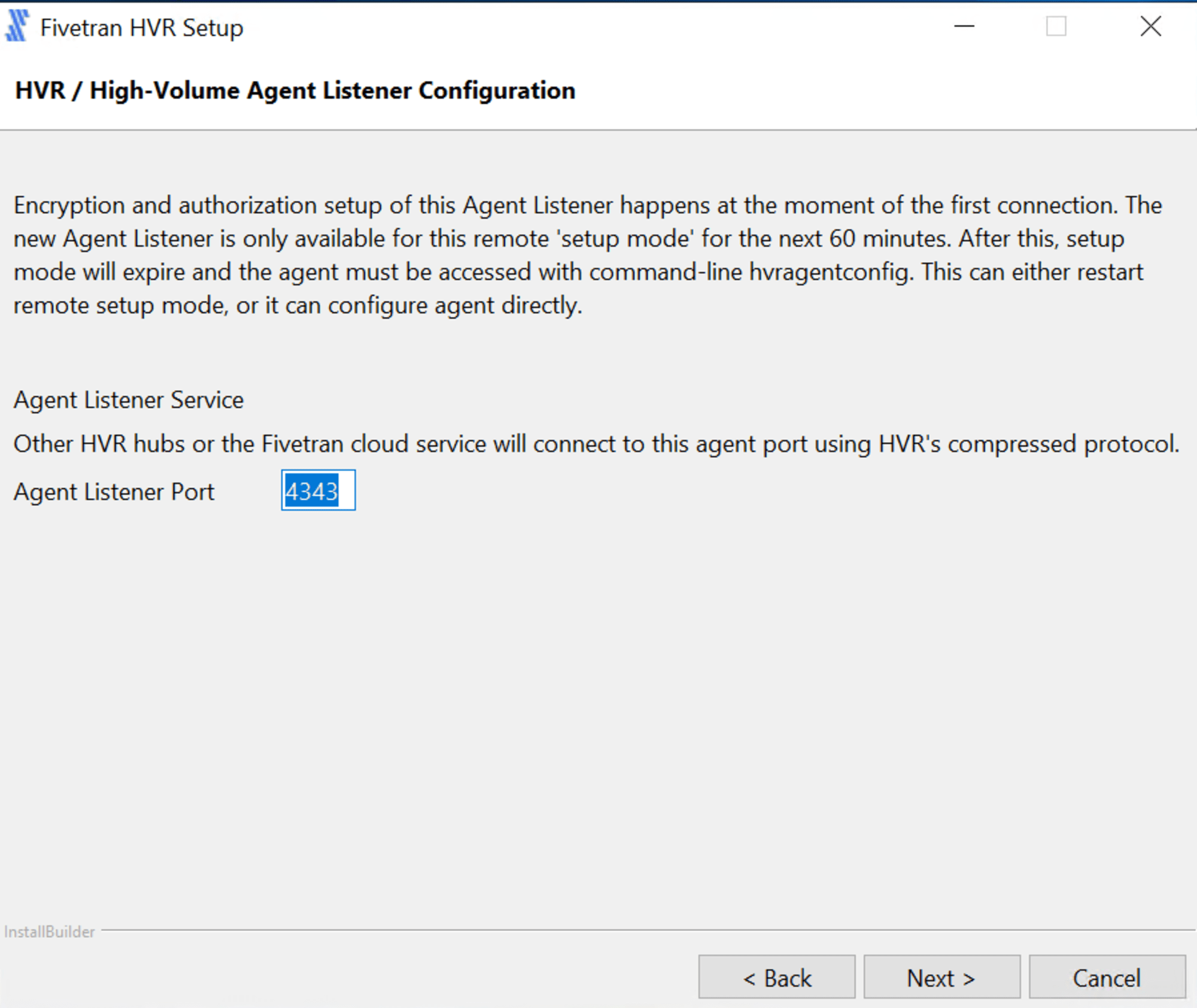
エージェントが使用するポートを指定します。デフォルトは 4343 です。
エージェントの実行ユーザーを指定します。ここでは Local System account としました。
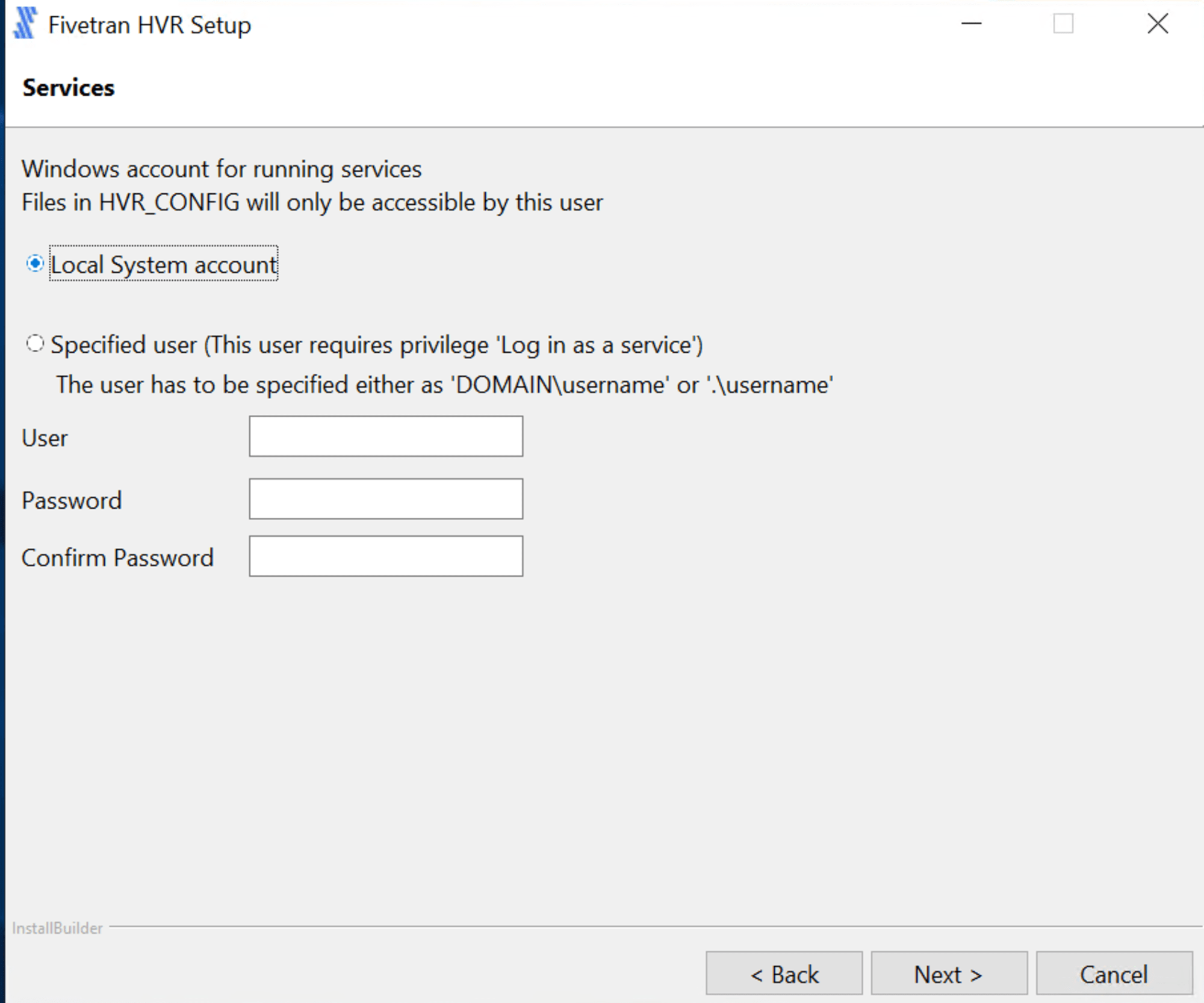
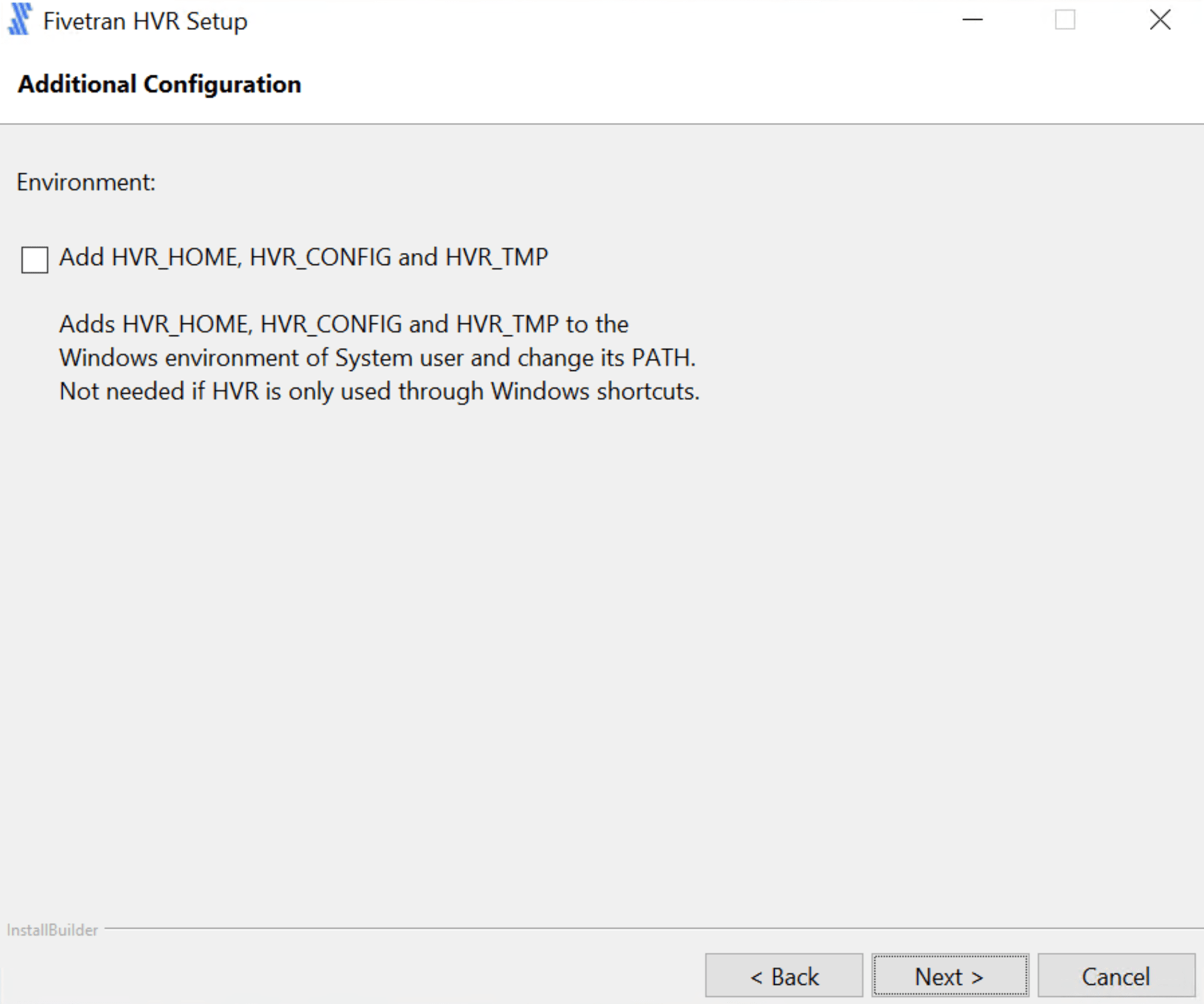
環境変数を追加する場合、下図にチェックを入れ [Next] をクリックします。
[Next] をクリックしインストールを開始します。
インストールが完了すると下図の表示となります。
HVA の構成
HVA のインストール後、構成を行います。構成手順は以下に記載があります。
コマンドプロンプトで以下を実行し、HVA ユーザーを作成します。ここで作成するユーザーのユーザー名とパスワードは接続設定時に使用します。
>hvragentuserconfig -c hva_user
Password for 'hva_user': <hva_user_password>
Retype password: <hva_user_password>
続けて、以下のコマンドでセットアップモードを無効化します。
>hvragentconfig Setup_Mode_Timed_Until=
hvragentconfig: Agent setup mode disabled.
HVA public certificate を抽出します。この出力値も後ほど使用するので安全な場所に控えておきます。
>hvragentconfig Agent_Server_Public_Certificate
Agent_Server_Public_Certificate=XXXXXX=
以下のコマンドで HVA を起動します。
hvragentlistener -acs 4343
サービスとしては下図のように表示されていました。

SQL Server の設定
SQL Server のインストール・初期設定
インストーラーを以下からダウンロードしインストールします。
インストールが完了後 sqlcmd で SQL Server にログインします。
sqlcmd -S <ホスト名> -E
ここでは以下の手順でサーバーの認証モードを混合モードに変更し、ユーザー名とパスワードによる認証を行えるようにしました。
続けて Fivetran からの接続に使用するユーザーを以下のコマンドで作成しました。
USE testdb;
CREATE LOGIN fivetran_user WITH PASSWORD ='<パスワード>'
CREATE USER fivetran_user FOR LOGIN fivetran_user;
ALTER LOGIN fivetran_user ENABLE;
ユーザー作成後は、SQL Server に接続可能なことを確かめておきます。
sqlcmd -S localhost -U fivetran_user -P <パスワード>
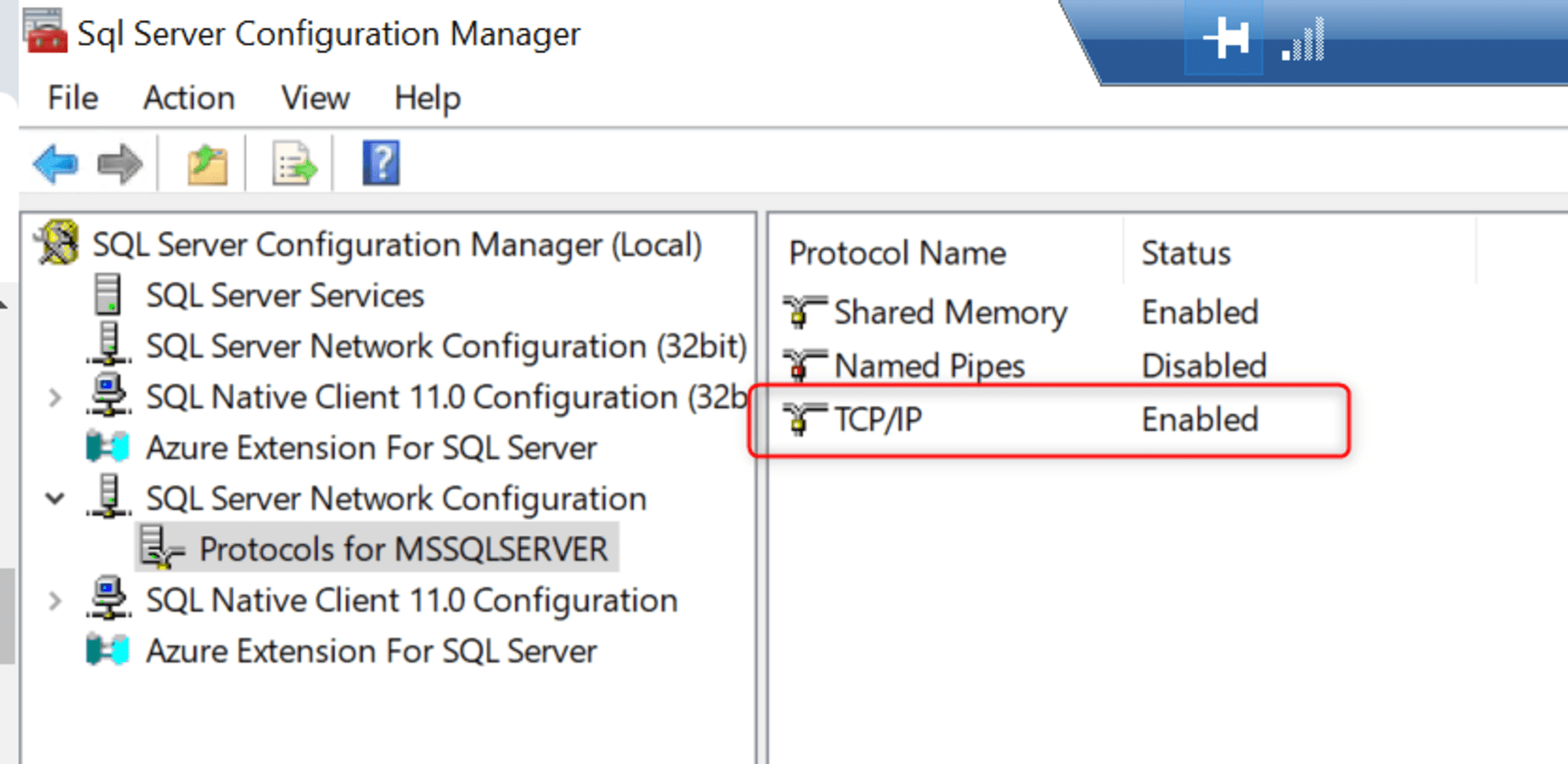
また、外部のサーバーから接続するために SQL Server 構成マネージャーを起動し「Protocol for MSSQLSERVER」の「TCP/IP」を「Enabled」に変更しました。
こちらは、はじめ接続テストがうまくいかず詰まっていたのですが、以下の記事を参考にさせていただきました。
サンプルデータの作成
権限のあるユーザーでログインし、以下のコマンドで Fivetran で連携するサンプルデータを作成しました。
データベースの作成
CREATE DATABASE testdb;
GO
テーブルの作成とデータの追加
-- テーブルの作成
CREATE TABLE sampledata (
id int primary key,
randomnumber int,
randomdate date,
randomstring varchar(100)
);
-- ランダムなデータを10,000件挿入
;WITH cte as (
SELECT TOP (10000)
row_number() over (order by (select null)) as rownum
FROM sys.columns a
CROSS JOIN sys.columns b
)
INSERT INTO sampledata (id, randomnumber, randomdate, randomstring)
SELECT
rownum,
abs(checksum(newid())) % 1000, -- 0から999までのランダムな数
dateadd(day, abs(checksum(newid())) % 3650, '2000-01-01'), -- 過去10年間のランダムな日付
left(convert(varchar(255), newid()), 10) -- ランダムな文字列
FROM cte;
確認
1> SELECT COUNT(*) FROM sampledata;
2> GO
-----------
10000
(1 rows affected)
復旧モデルの確認
以下のコマンドで復旧モデルが完全であることを確認します。
1> SELECT name, recovery_model_desc
2> FROM sys.databases
3> WHERE name = 'model';
4> GO
name recovery_model_desc
------------------- -------------------
model FULL
(1 rows affected)
権限設定
SQL Server の変更をキャプチャする際は3種類の権限モデルを使用できます。
- SysAdmin モデル
- 設定が用意だが、SQL Server 全体に対して広い権限を有するため、潜在的なセキュリティリスクを伴う
- DbOwner モデル
- 特定のデータベースに対して広い権限を持つ
- SysAdmin モデルよりも設定に手間がかかる
- Minimal モデル
- 最小権限での操作とできるが、設定が複雑
それぞれに特徴があるので、環境にあったものを選択ください。詳細は以下に記載があります。
ここでは DbOwner モデルで Fivetran 用の権限を設定しました。
はじめに、同期対象となるデータベースの所有者を変更します。
ALTER ROLE db_owner ADD MEMBER fivetran_user;
次に、msdbデータベースに特別なストアドプロシージャを作成します。ストアドプロシージャの作成コマンドは HVA のインストールとあわせて以下に格納されます。
%HVR_HOME%\dbms\sqlserver
ここでは、msdb 上で以下を実行しスクリプトを実行しました。
:r D:\Fivetran\hvr_home\dbms\sqlserver\hvrcapdbowner.sql
:r D:\Fivetran\hvr_home\dbms\sqlserver\hvrcapsysadmin.sql
スクリプト実行後、 sp_hvr_dblog, sp_hvr_dbtable, sp_hvr_loginfo の3つのストアドプロシージャが作成されていることが確認できます。(関数は読み取り専用)
1> SELECT name
2> FROM sys.procedures
3> WHERE name IN ('sp_hvr_dblog', 'sp_hvr_dbtable', 'sp_hvr_loginfo');
4> GO
name
--------------------------------------------------------------------------------------------------------------------------------
sp_hvr_dblog
sp_hvr_dbtable
sp_hvr_loginfo
(3 rows affected)
その後、Fivetran 用のユーザーに対してこれらのプロシージャの実行を許可します。
use msdb;
create user fivetran_user for login fivetran_user;
grant execute on sp_hvr_dblog to fivetran_user;
grant execute on sp_hvr_dbtable to fivetran_user;
grant execute on sp_hvr_loginfo to fivetran_user;
続けてデータベース上の特別な読み取り専用権限を付与します。具体的には以下を付与します。
- SQL Server 2022
VIEW SERVER PERFORMANCE STATE
- 上記以外
VIEW SERVER STATE
今回の検証では SQL Server 2022 を使用しているため、以下のコマンドを使用しました。
use master;
grant view server performance state to fivetran_user;
Supplemental logging の有効化
さいごに HVA がログベースのキャプチャを行うために補足ログを有効化します。
use <対象のデータベース>
go
set implicit_transactions off
go
—- Enable CDC on the database
EXEC sp_cdc_enable_db
go
Fivetran:コネクタの構成
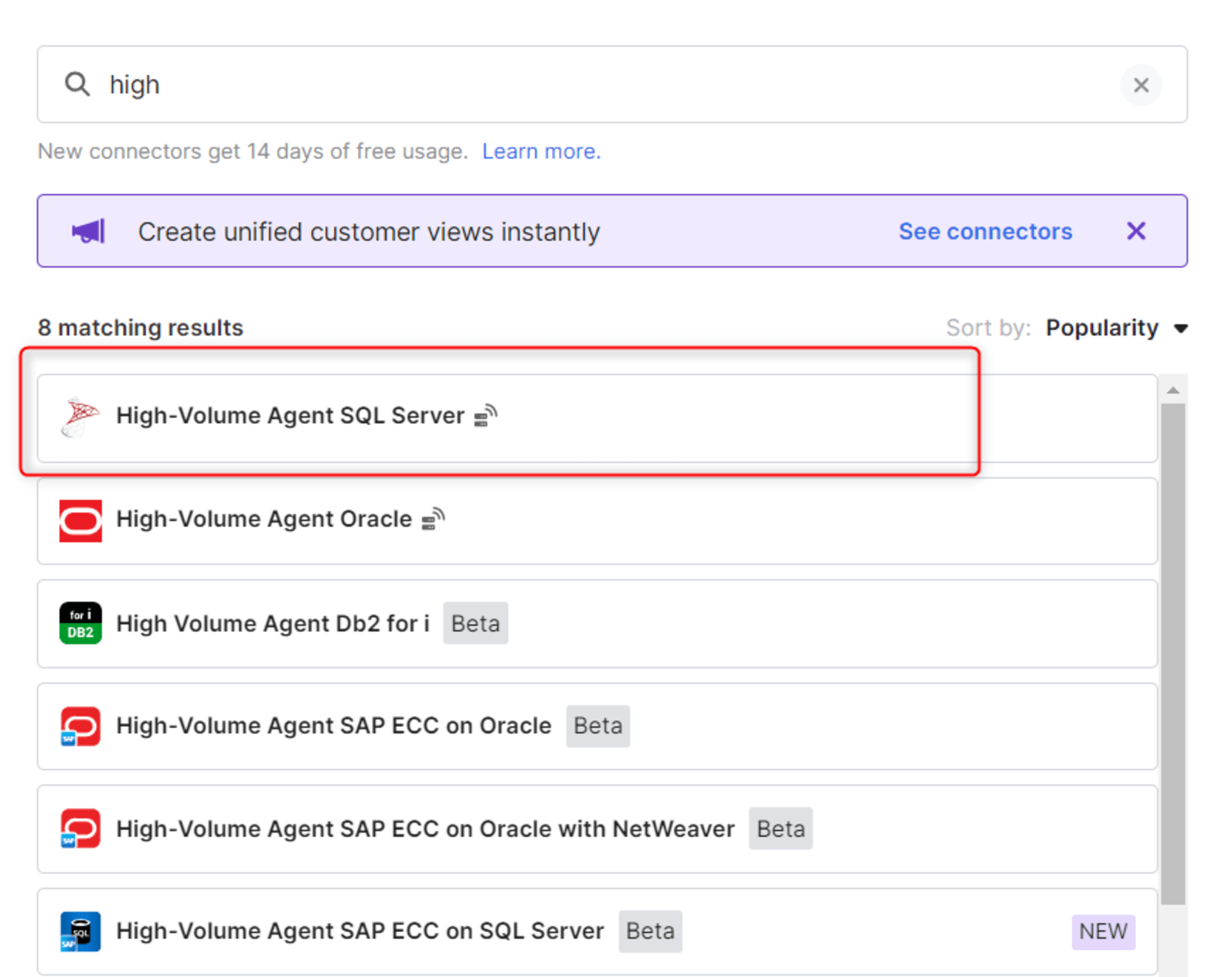
コネクタとして「High-Volume Agent SQL Server」を指定します。
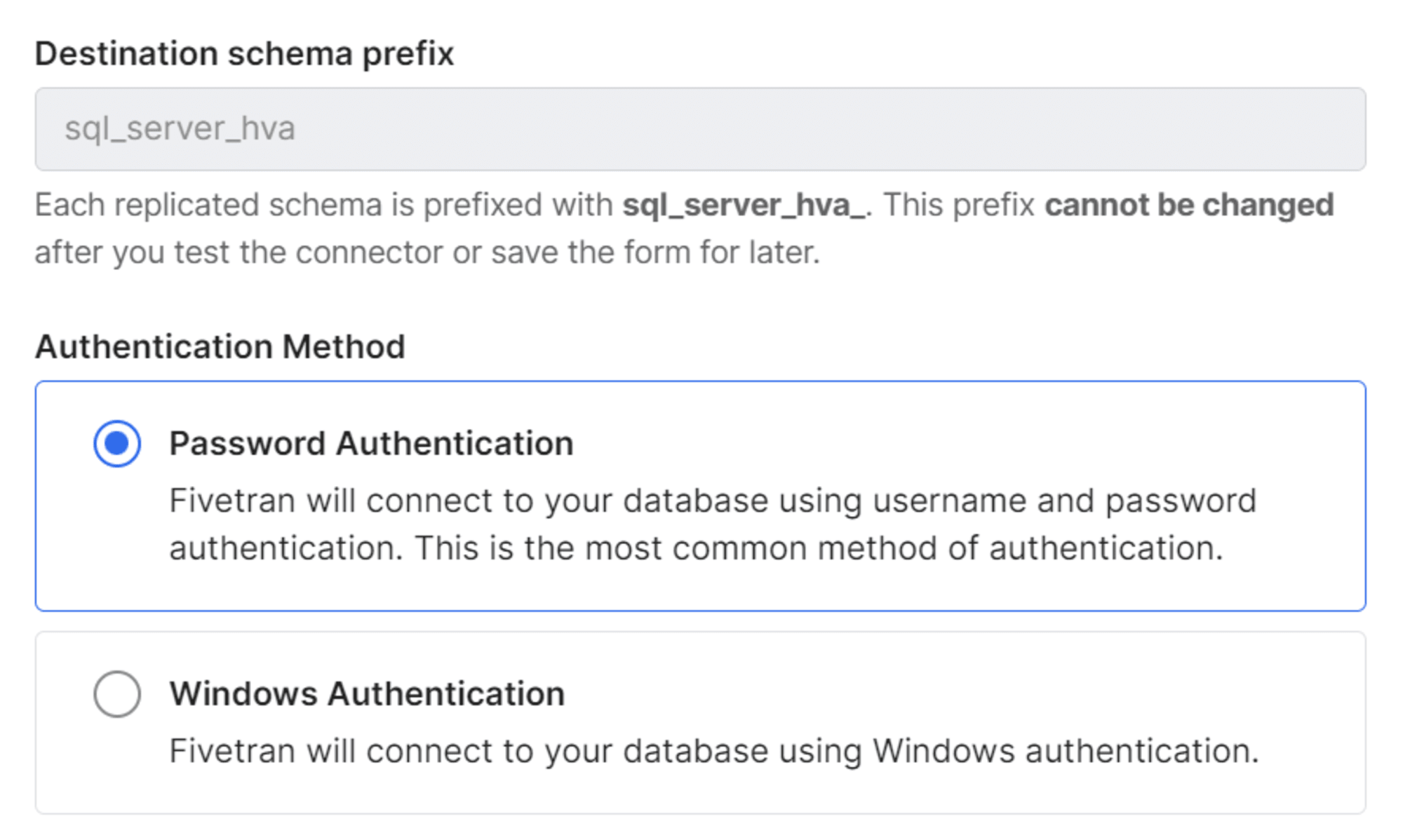
はじめに「Destination schema prefix」と「Authentication Method」を指定します。スキーマプレフィックスのデフォルトはsql_server_hva となっており、宛先 DWH にsql_server_hva_<ソーススキーマ名> としてスキーマが構成されます。
次の項目では、エージェントから見た際のソースシステムの情報を入力します。
具体的には下図の項目です。
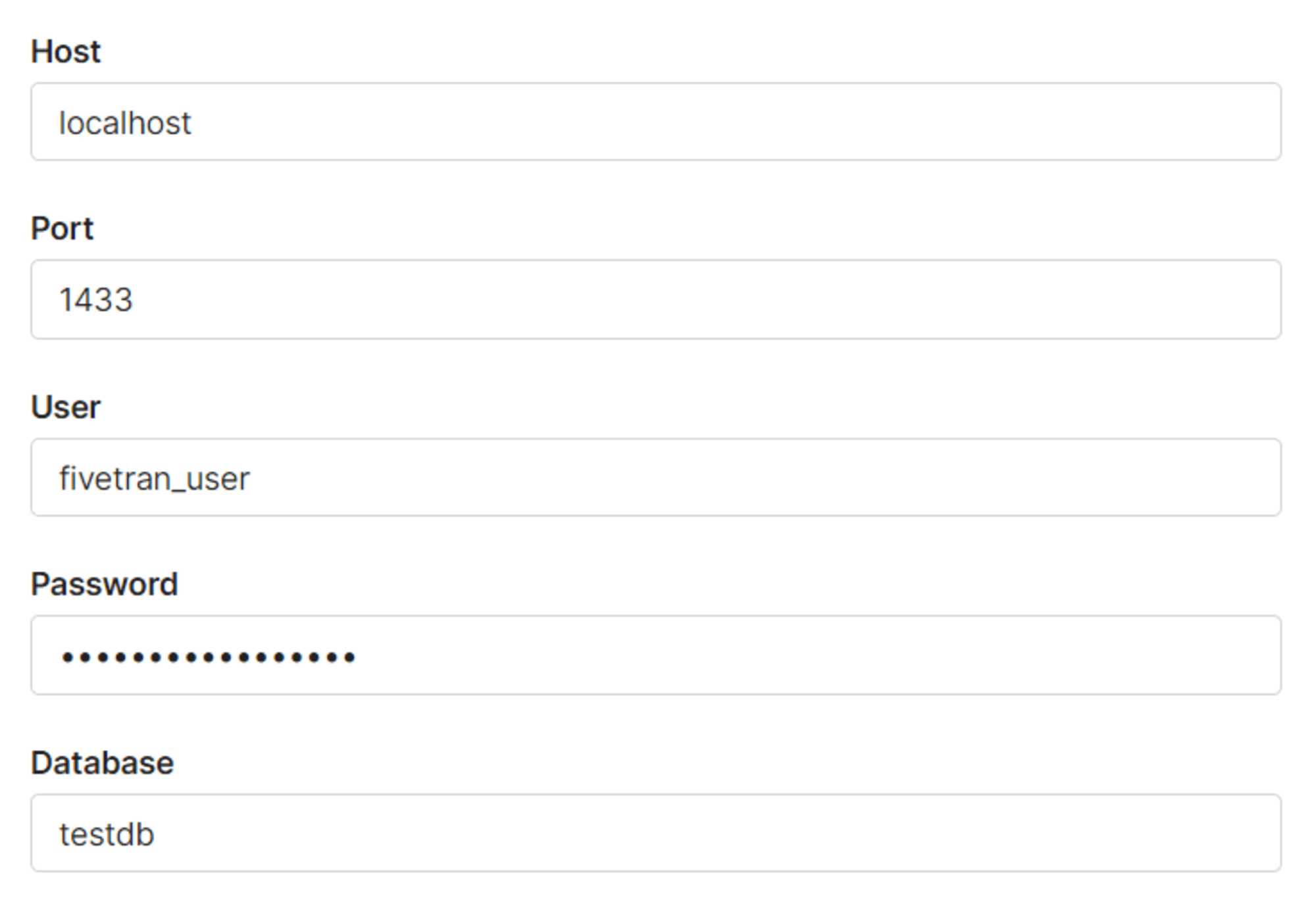
- Host
- ソースシステムのホスト。エージェントと SQL Server を同じマシンにインストールしている場合は
localhostと入力
- ソースシステムのホスト。エージェントと SQL Server を同じマシンにインストールしている場合は
- Port
- SQL Server が実行されているポート番号
- ユーザー名、パスワード
- SQLServer 上の Fivetran 用ユーザーの情報認証情報
- Database
- 同期対象のデータベース
続けて、接続方法を指定します。ここでは SSH トンネルを使用するので、下図の項目を指定します。
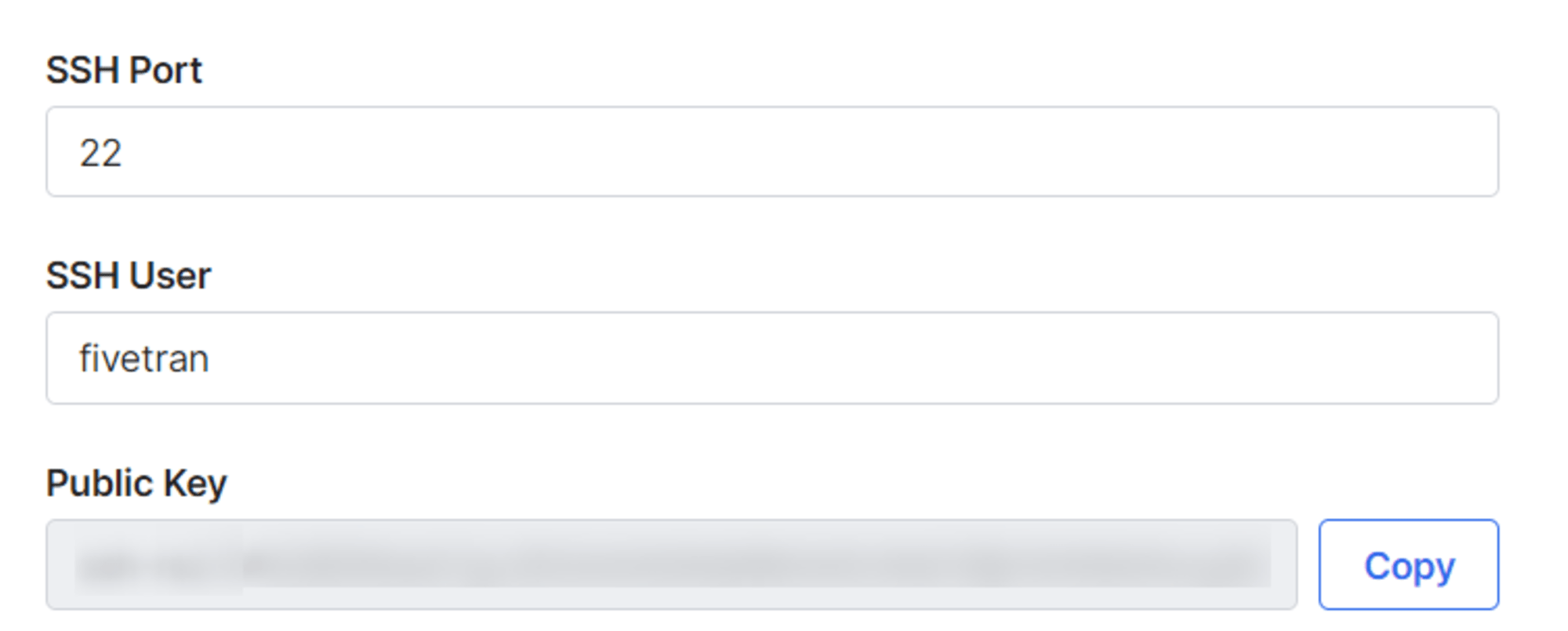
- SSH Port:デフォルトは 22
- SSH User:SSH サーバー上に作成した専用のユーザー
- Public Key:上記ユーザーの
.sshディレクトリに登録
こちらの構成手順の詳細は以下をご参照ください。
必要に応じてさらに以下の項目を設定します。

データの更新方法として Archive Log Only を使用する場合は、ここで「Use archive log only mode」のトグルをオンにします。
その他の項目は以下をご参照ください。
さいごにエージェントに関する情報を入力します。具体的な項目は以下です。
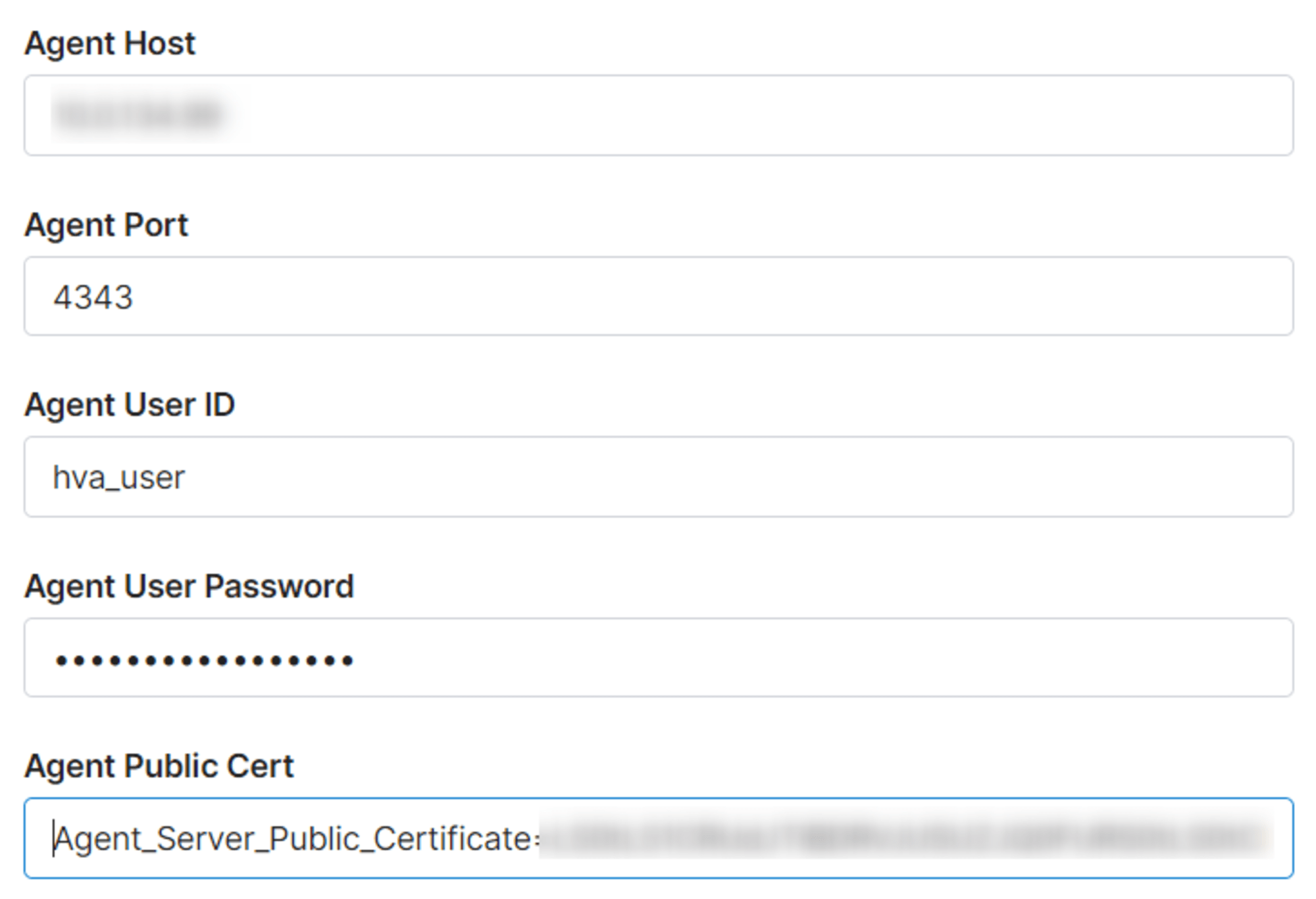
- Agent Host
- HVA をインストールしたマシンのホスト名や IP アドレスを
- SSHトンネルの場合はプライベートネットネットワークの IP アドレス
- Agent Port
- デフォルト値から変更がなければ 4343
- Agent User ID、Agent User Password
- HVA の構成で作成したユーザー情報
- Agent Public Cert
- HVA の構成で抽出した public certificate の出力値
他にもセキュリティグループで以下の通信を許可するネットワーク設定を実施しておきます。
- SSH サーバーに対してFivetran IP からのポート 22 の通信
- SQL Server マシンに対して SSH サーバーからのポート 4343 の通信
設定完了後、接続テストを実施します。
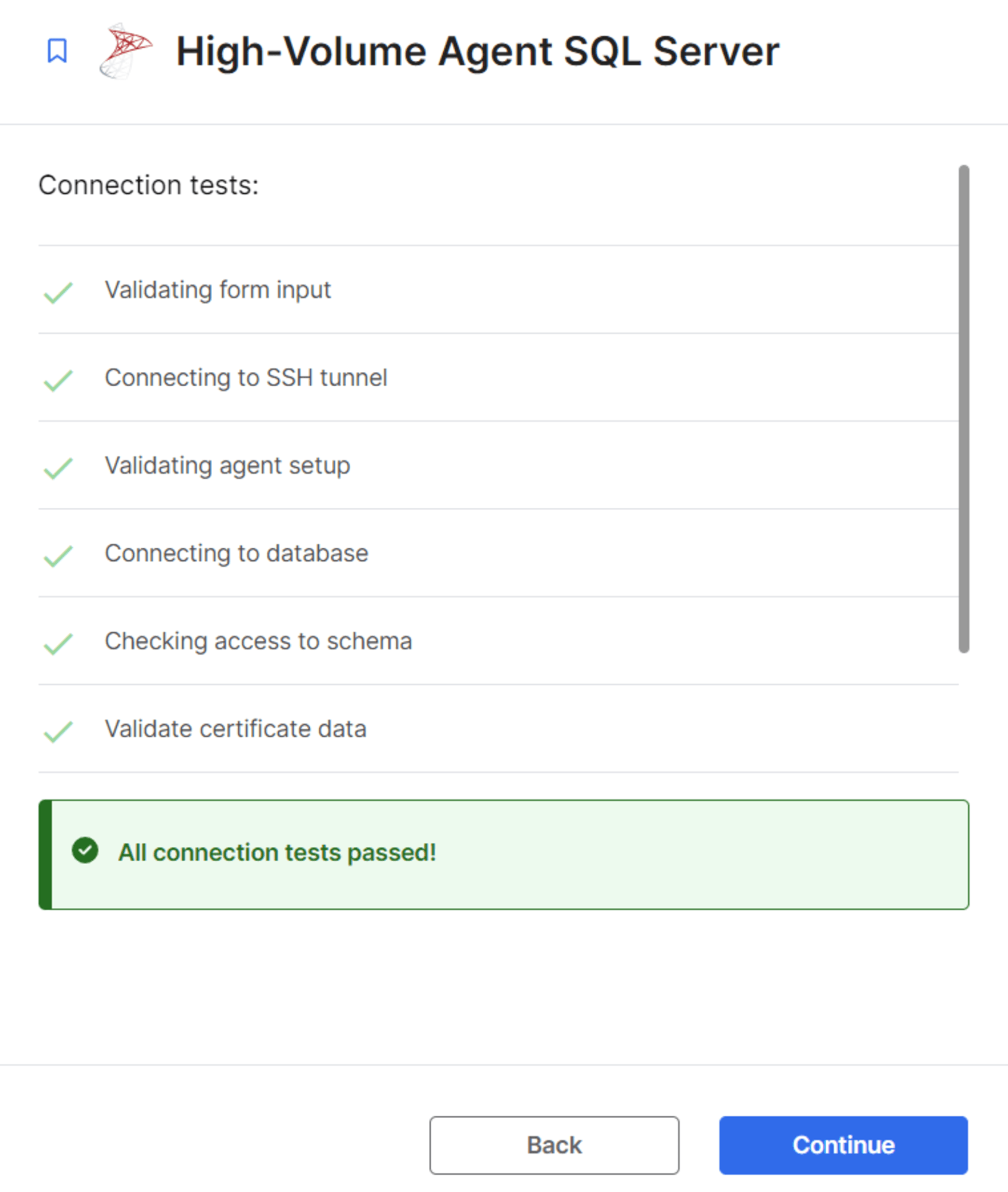
テストが完了するとスキーマ情報が取得されるので、同期するデータにチェックを入れます。
スキーマの変更としてどこまで追従するかを指定します。
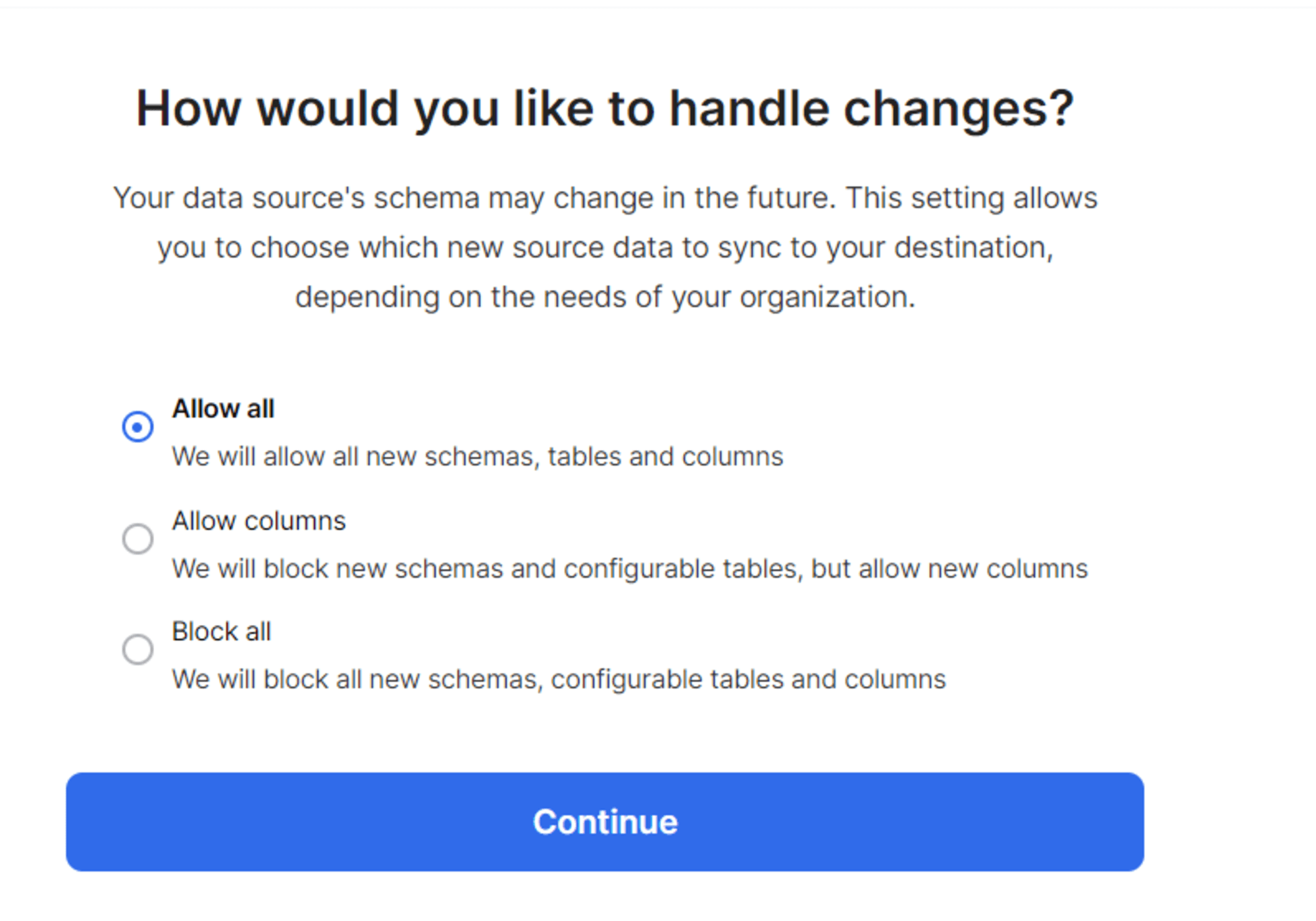
上記の手順で設定完了です。
初期同期
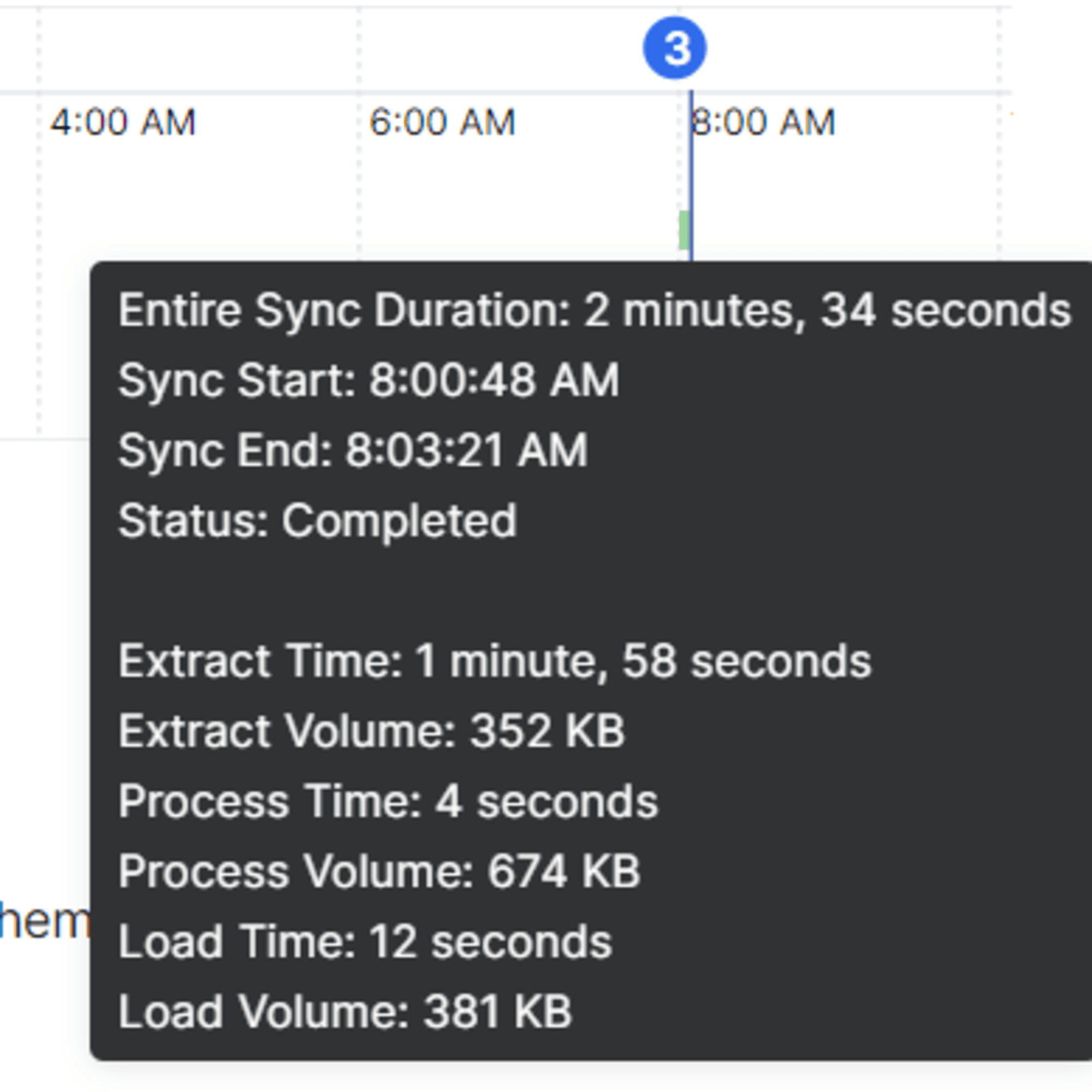
設定完了後、初期同期を実施できます。今回の環境では 10,000件のレコードからなる単一のテーブルの同期で2分半程度要しました。
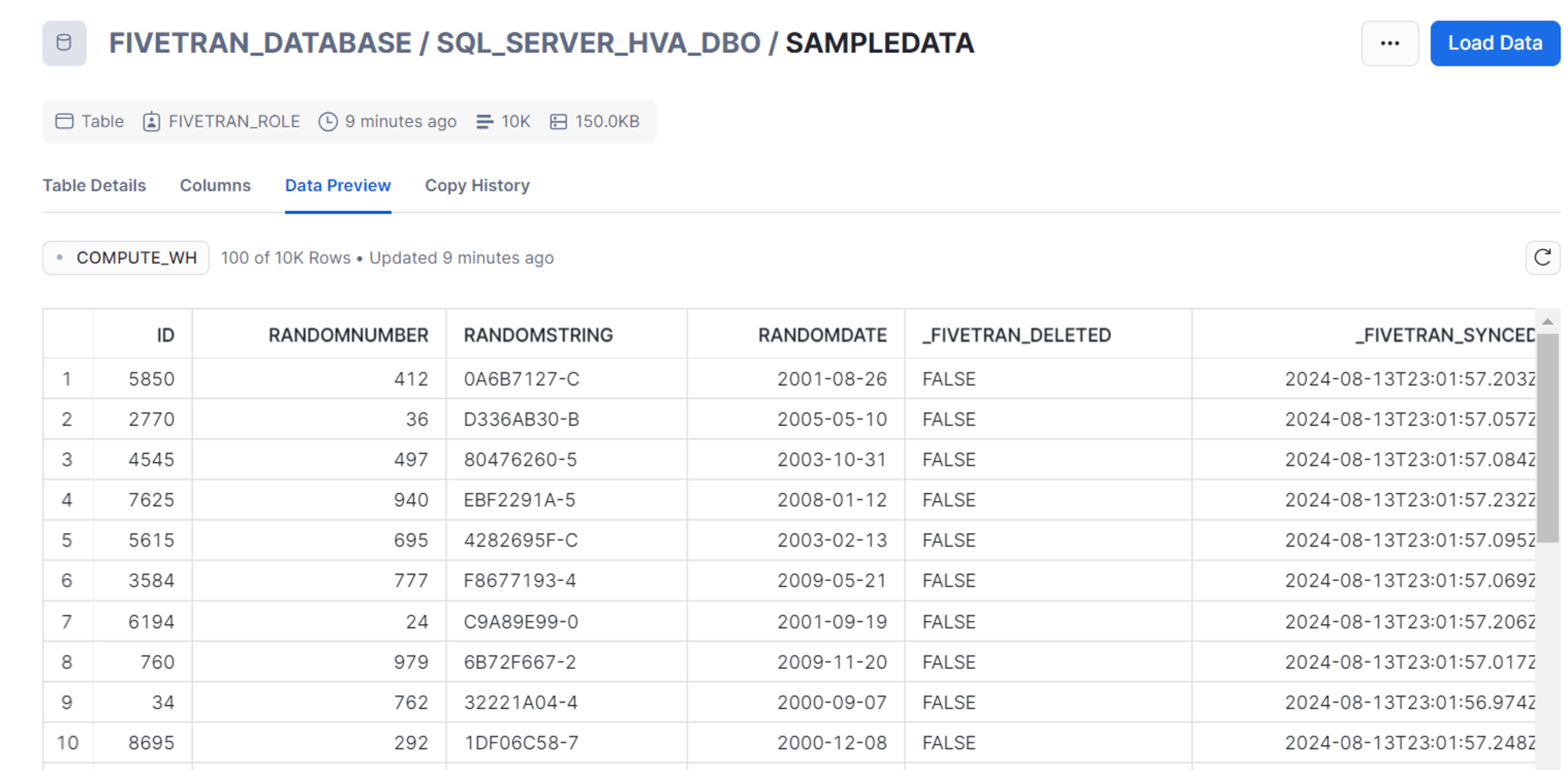
同期完了後、Snowflake でもレコードを確認できます。
データの更新
基本的なデータ更新の動作を確認してみます。
レコードの追加
以下のコマンドで SQL Server 側で 1,000件のレコードを追加します。
-- 最大IDを取得
DECLARE @maxId int;
SELECT @maxId = ISNULL(MAX(id), 0) FROM sampledata;
-- ランダムなデータの挿入
;WITH cte as (
SELECT TOP (1000)
row_number() over (order by (select null)) + @maxId as rownum
FROM sys.columns a
CROSS JOIN sys.columns b
)
INSERT INTO sampledata (id, randomnumber, randomdate, randomstring)
SELECT
rownum,
abs(checksum(newid())) % 1000, -- 0から999までのランダムな数
dateadd(day, abs(checksum(newid())) % 3650, '2000-01-01'), -- 過去10年間のランダムな日付
left(convert(varchar(255), newid()), 10) -- ランダムな文字列
FROM cte;
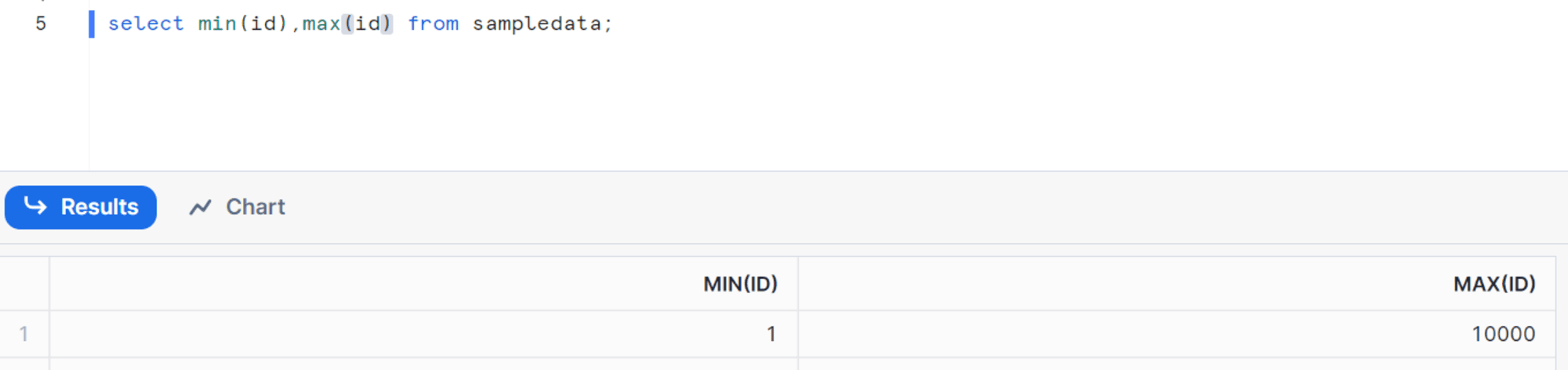
SQL Server で確認
1> select min(id),max(id) from sampledata;
2> go
----------- -----------
1 11000
(1 rows affected)
同期完了後、Snowflake でも追加されたレコードを確認できます。
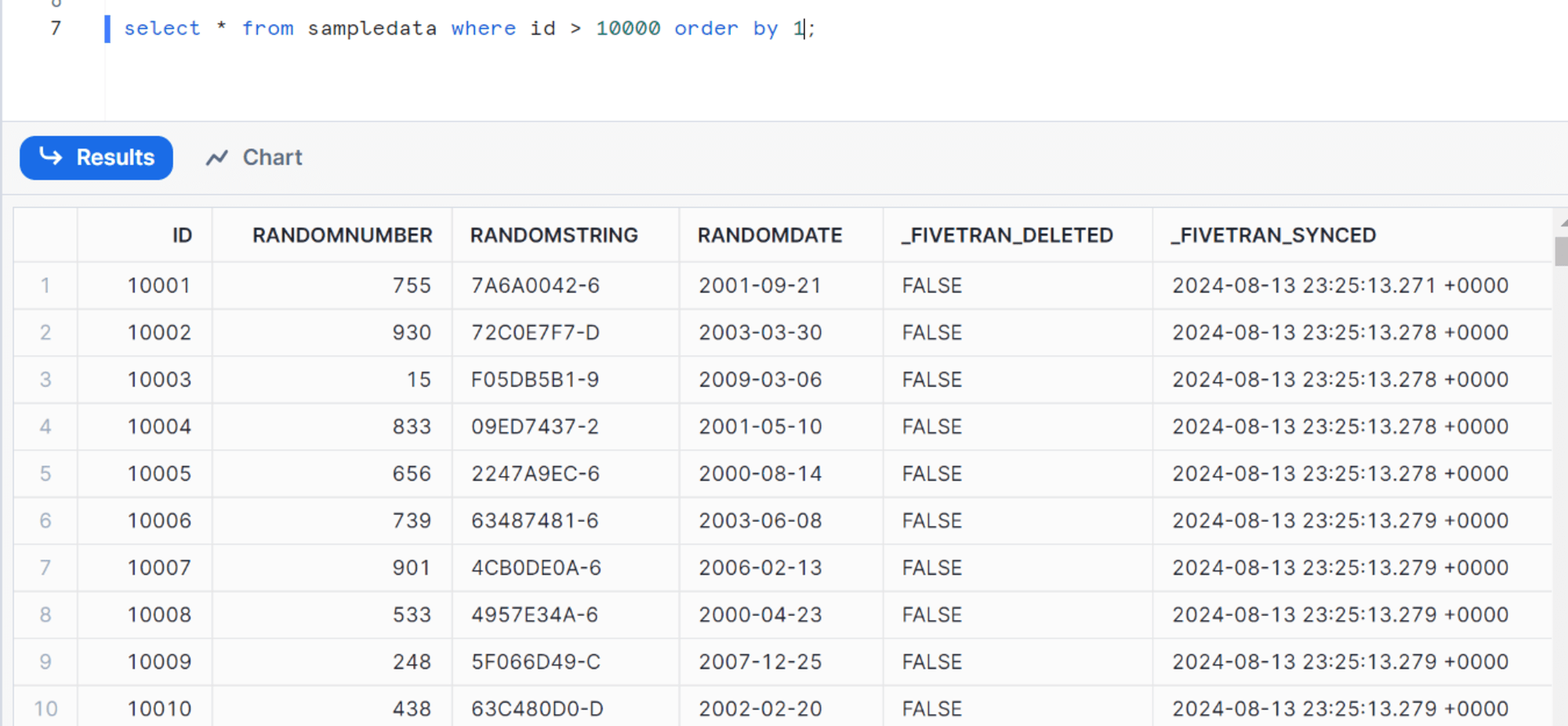
レコードの削除
[id] が最初の10件のレコードを削除してみます。
--idカラムの最初の10件のレコードを削除
DELETE FROM sampledata
WHERE id IN (
SELECT TOP 10 id
FROM sampledata
ORDER BY id
);
1> select min(id),max(id) from sampledata;
2> go
----------- -----------
11 11000
(1 rows affected)
同期完了後、Snowflake で確認すると「_FIVETRAN_DELETED」が True に変更され論理削除が行われていることを確認できます。
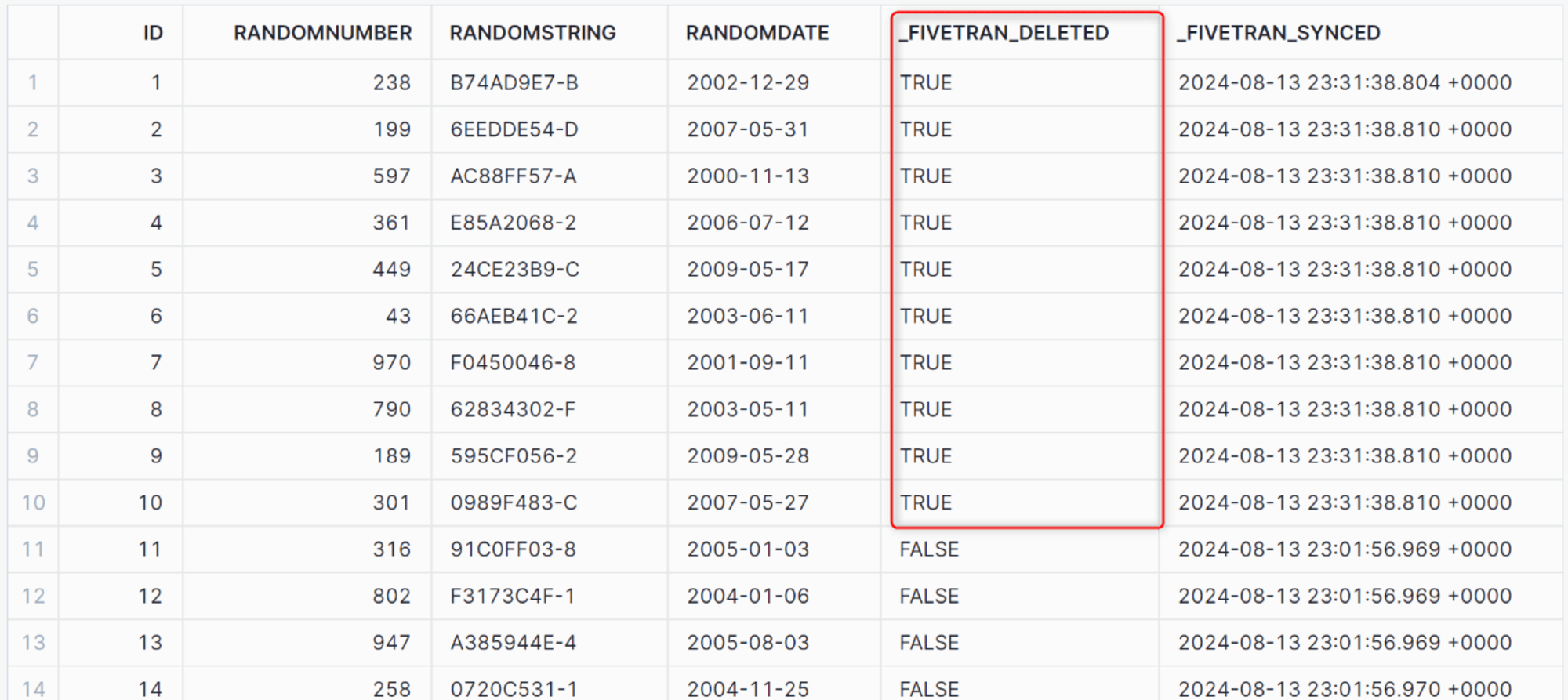
レコードの変更
[id] の値が 11 のレコードを変更します。
変更前
1> select * from sampledata where id = 11;
2> go
id randomnumber randomdate randomstring
----------- ------------ ---------------- ----------------------------------------------------------------------------------------------------
11 316 2005-01-03 91C0FF03-8
(1 rows affected)
変更内容
UPDATE sampledata
SET randomnumber = 500,
randomstring = 'updated'
WHERE id = 11;
同期完了後、Snowflakeで確認すると、変更がキャプチャされていることが確認できます。

列の追加
テーブル構造の変化を伴う列の追加を行います。
ALTER TABLE sampledata
ADD description VARCHAR(255);
コネクタの「Schema」タブからもスキーマの変更がすぐにキャプチャされます。
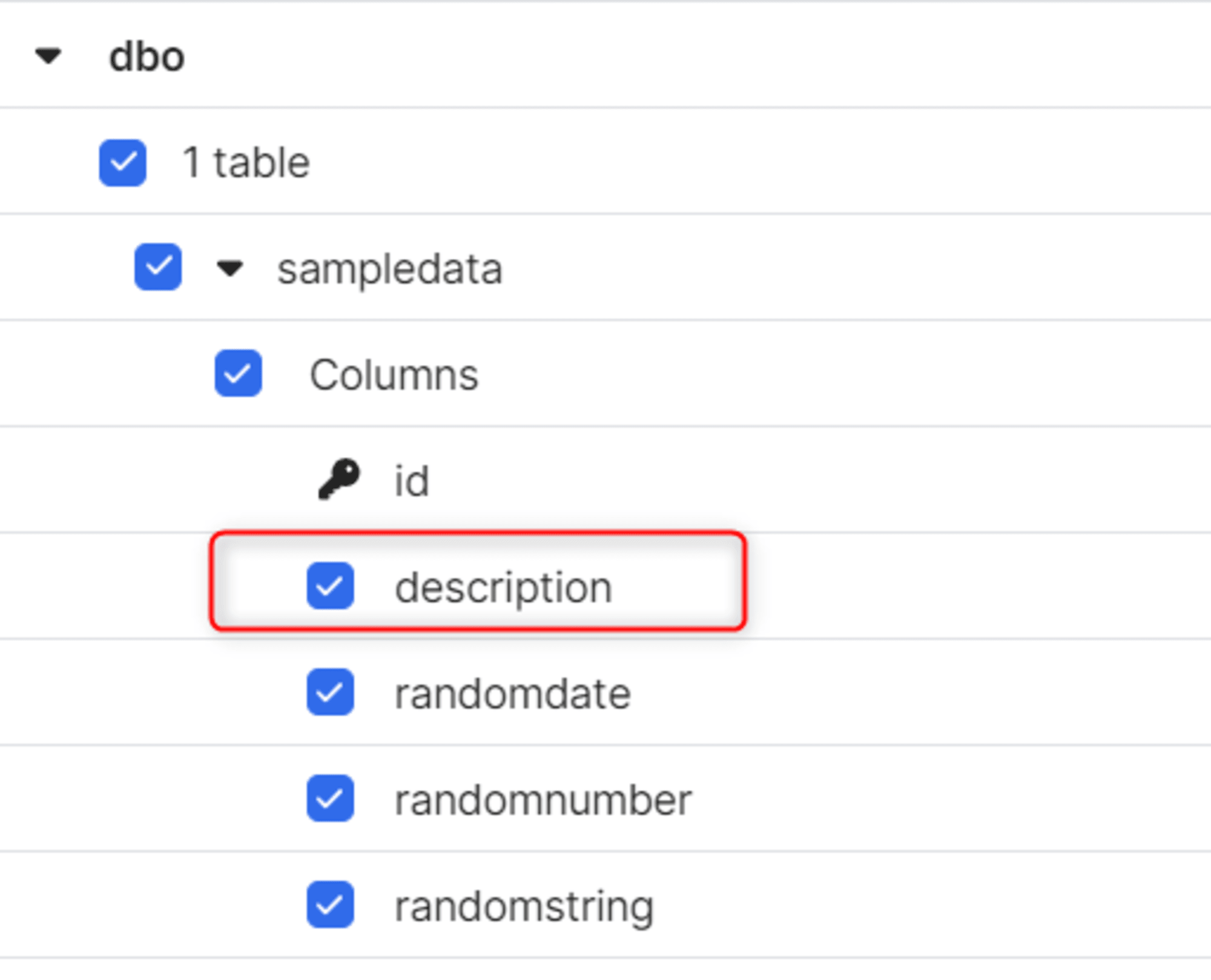
同期が完了すると、Snowflake 側にも追加されます。
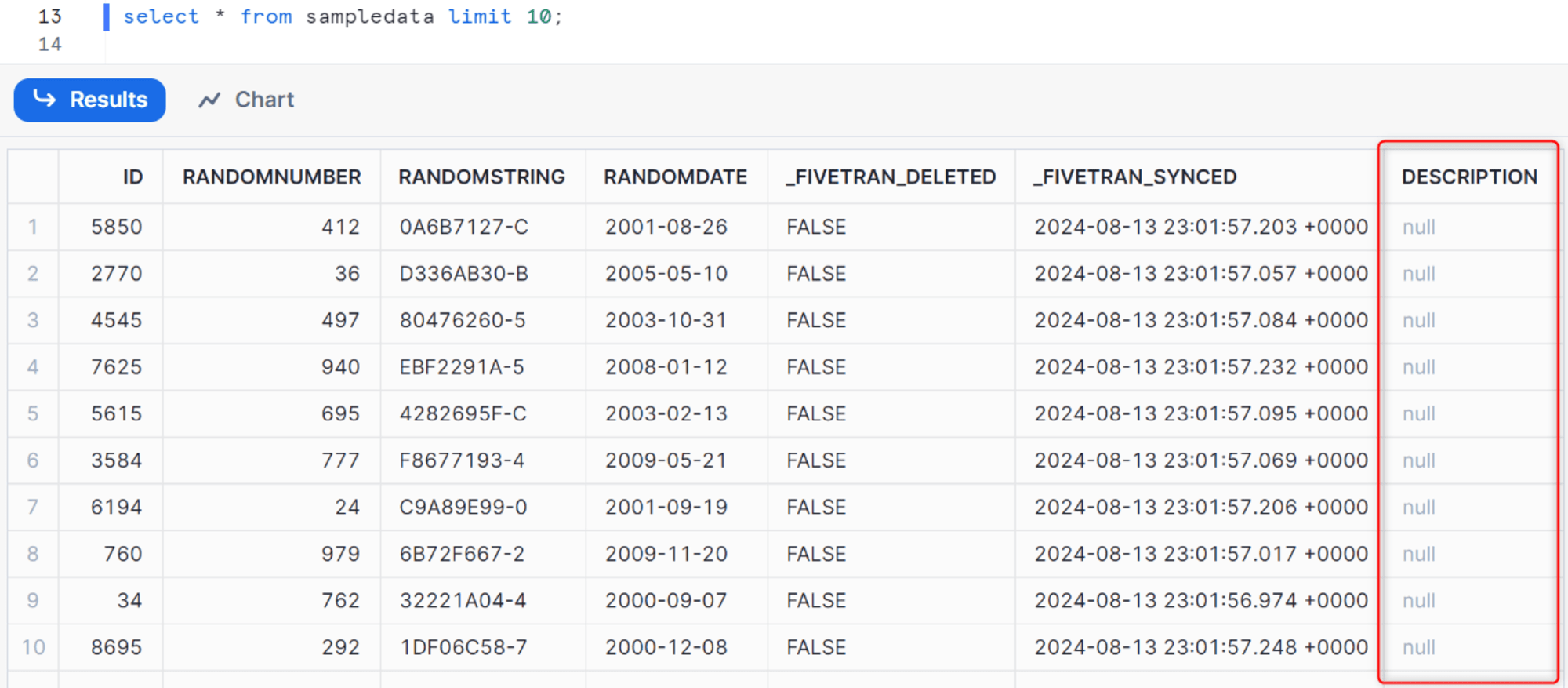
列の削除
[randomdate] カラムを削除してみます。
ALTER TABLE sampledata
DROP COLUMN randomdate;
Fivetran 側でスキーマを確認すると、以下のように表示されなくなります。
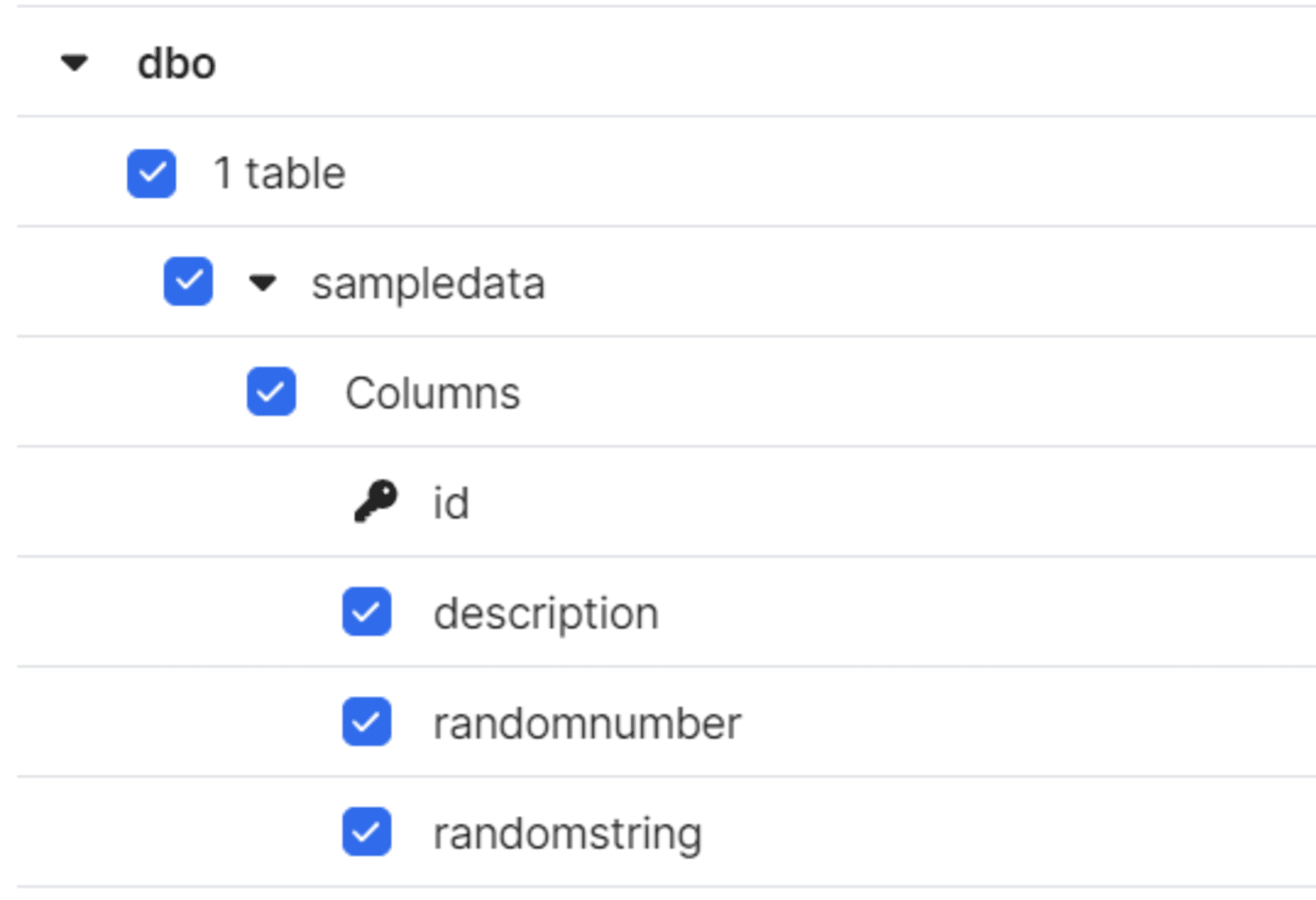
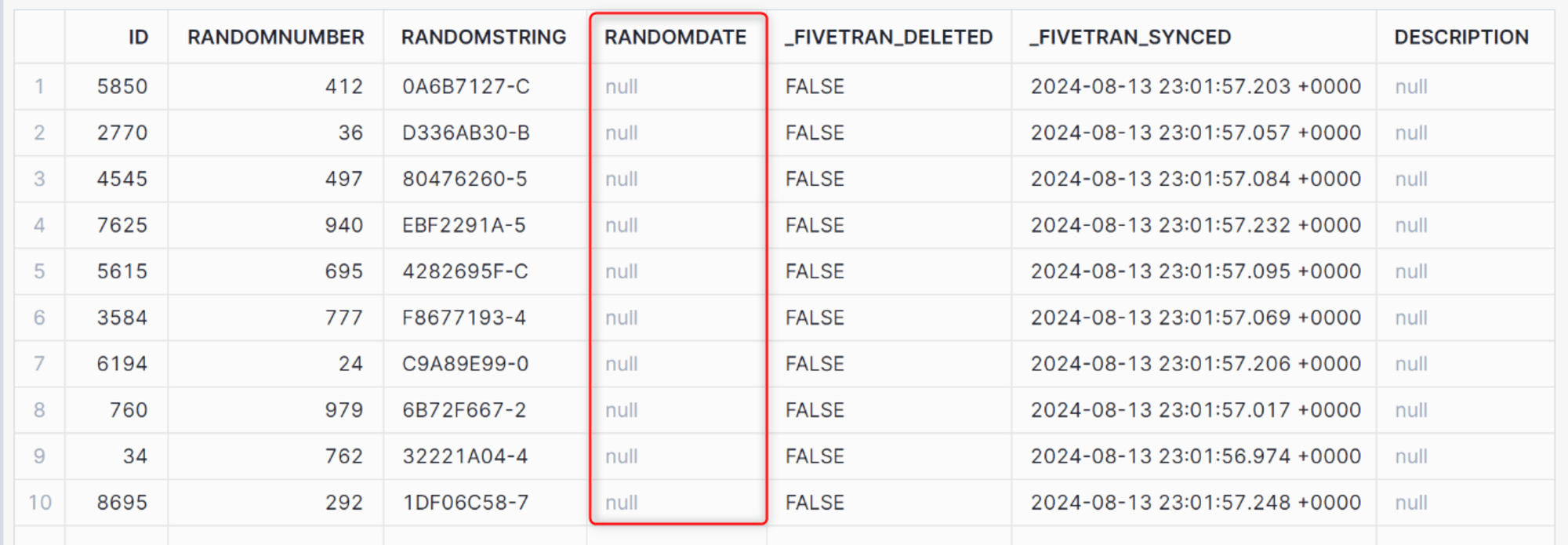
同期後、Snowflakeで確認するとソースから削除された列は、宛先にそのまま保持される代わりに、宛先の対応する列の値には Null が書き込まれる形で反映されます。
テーブルの追加
同期済みのテーブルと同じスキーマにテーブルを追加してみます。
-- テーブルの作成
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(100),
created_at DATE
);
-- サンプルデータの挿入
INSERT INTO customers (customer_id, first_name, last_name, email, created_at)
VALUES
(1, 'John', 'Doe', 'john.doe@example.com', '2024-08-13'),
(2, 'Jane', 'Smith', 'jane.smith@example.com', '2024-08-12'),
(3, 'Michael', 'Johnson', 'michael.johnson@example.com', '2024-08-11');
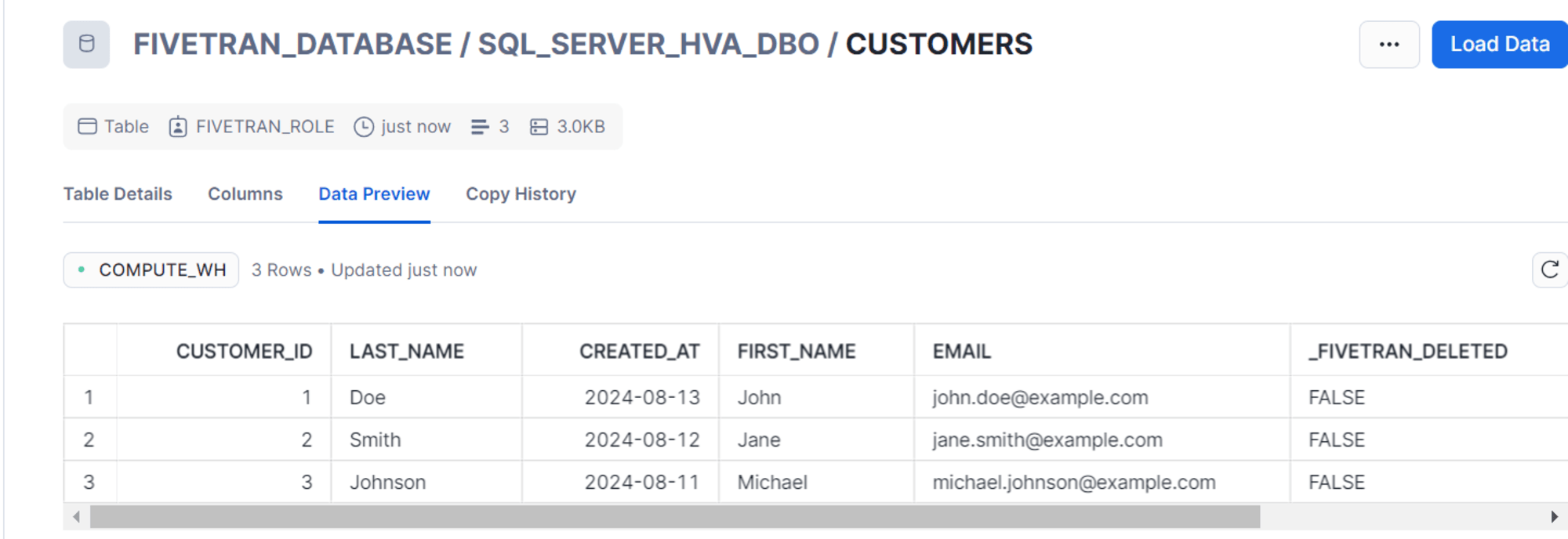
Fivetranでもすぐに変更が反映されます。

同期完了後、Snowflake 側でも自動的にテーブルの追加を確認できます。
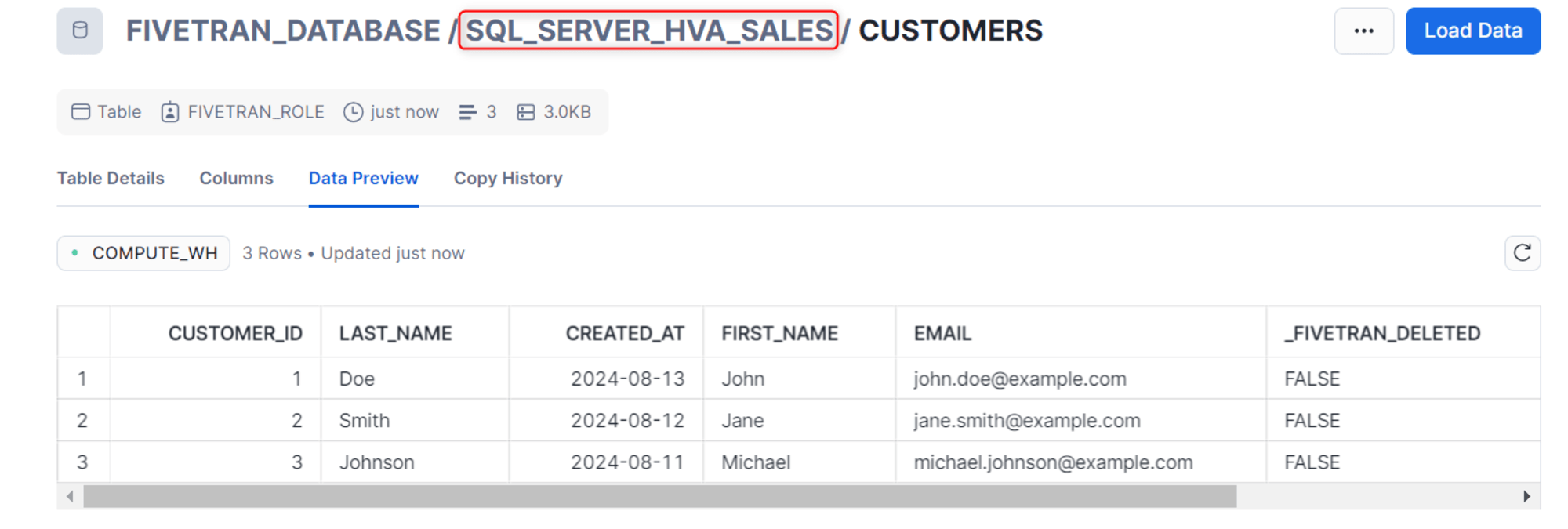
スキーマの追加
さいごにスキーマの追加を試してみます。
-- 新しいスキーマの作成
CREATE SCHEMA sales;
-- salesスキーマ内にcustomersテーブルを作成
CREATE TABLE sales.customers (
customer_id INT PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(100),
created_at DATE
);
-- サンプルデータの挿入
INSERT INTO sales.customers (customer_id, first_name, last_name, email, created_at)
VALUES
(1, 'John', 'Doe', 'john.doe@example.com', '2024-08-13'),
(2, 'Jane', 'Smith', 'jane.smith@example.com', '2024-08-12'),
(3, 'Michael', 'Johnson', 'michael.johnson@example.com', '2024-08-11');
テーブルを作成後、Fivetran 側でも検知されます。
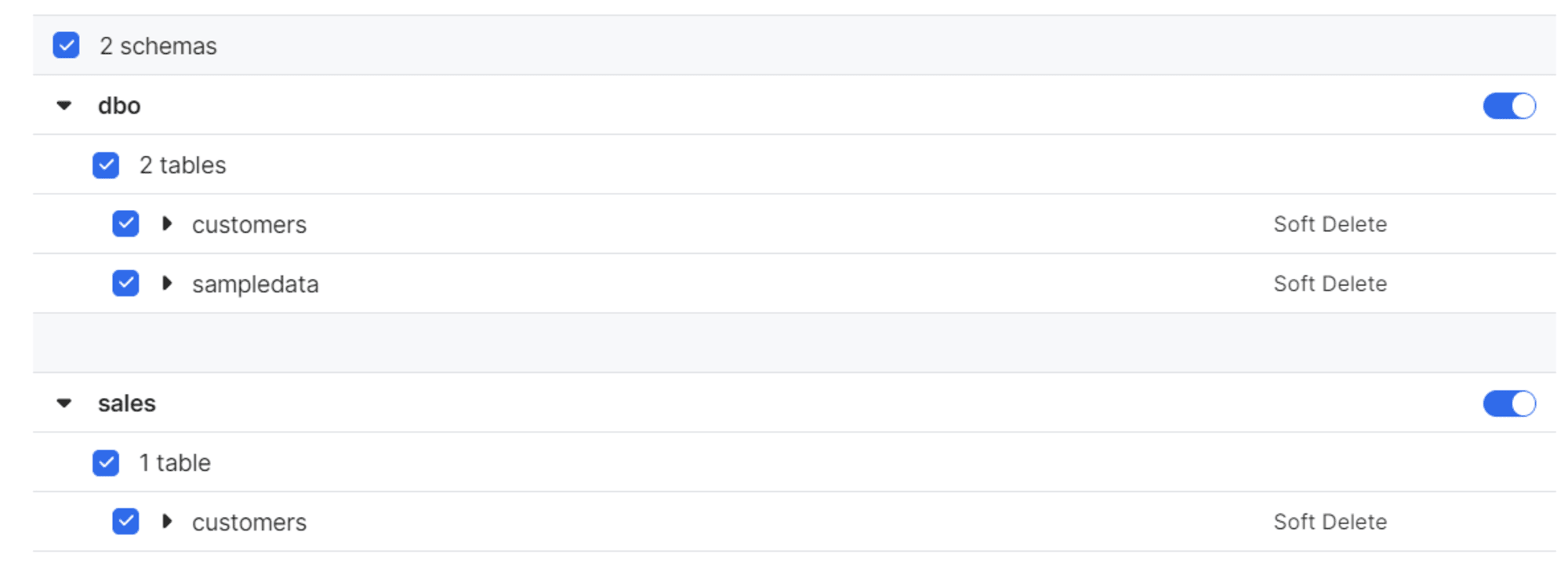
同期完了後は、別のスキーマに作成されたことを確認できました。
さいごに
HVA を使用した SQL Server のデータ同期を試してみました。通常のコネクタとは異なる設定が必要となるので注意が必要と感じました。特に大規模データを連携する際は、Fivetran としても使用を推奨している機能になるため、こちらの内容が何かの参考になれば幸いです。







